8. Rekurentní sítě
Definice¶
- Neuronové sítě s pamětí. Architektura obsahuje alespoň jeden cyklus, kde se mezi časovými kroky předává vstup a zachovává se tak část dřívější informace. S přibývajícím časem je podíl nějaké konkrétní informace menší a menší, větší důraz je na nedávné vstupy.
- Vstupy (např. slova) mohou mít různé délky, které se vždy zakódují na stejnou velikost, aby vstupy mohly být zpracovány stejnou architekturou.
- RNNs využívají sdílení parametrů mezi časovými kroky, jelikož lze předpokládat, že určité příznaky se mohou vyskytovat v různých částech sekvence (podobně jako CNN mají sdílené filtery pro různé regiony v obrázku). Např. pro věty „Včera jsem snědl jablko“ a „Jablko jsem snědl včera“ se díky sdíleným parametrům stačí naučit význam věty jen jednou, kdyby nedocházelo ke sdílení parametrů, tak bychom sít museli učit zvlášť pro všechny pozice výskytu těchto slov.
Použiti¶
- Překlad, NLP, speech recognition, image captioning.
Otázky¶
Co je backprop in time?¶
Backpropagation through time (BPTT)¶
- Způsob trénování RNN, je podobný jako klasická backpropagace, kde se počítá odhad chyby od výstupní vrstvy postupně ke vstupům.
- Chyby se napříč časovými kroky sčítají (u Feed forward sítí to není třeba, jelikož nesdílejí parametry).
- Konceptuálně funguje optimalizace tak, že se síť rozbalí (unfold/unroll) do jednotlivých časových kroků (sada kopií sítě) a chyba sítě je spočtena a kumulativně sečtena postupně pro každý krok. Poté se síť opět poskládá a dojde k aktualizaci vah. To znamená, že pokud je vstup sekvence tisíce kroků, pak toto bude číslo kolikrát je třeba spočítat derivace pro jediný update vah, což může vést k vanishing (jde k nule) či exploding (jde k jednicce) gradients problému.
- BPTT se liší od běžného backpropagation tím, že se při aktualizaci vah vrací až do počátku sekvence vstupních dat, nikoli pouze do posledního kroku. To umožňuje RNN zpracovat dlouhé sekvence dat a zohlednit kontext z předchozích kroků při vytváření předpovědí.
- Existuje i Truncated backpropagation through time (TBPTT): Vstup je rozdělen na kratší sekvence a síti je na vstup poskytnuta jedna podsekvence k kroků (k vstupů a výstupů), pro kterou je sít rozbalena, vypočteny kumulativní chyby, updatnuty váhy. Toto je postupně provedeno pro všechny podsekvence.
Jak vypadá Elmanova, Hopfieldova síť?¶
Elmanova síť (Vanilla RNN)¶
- Feedforward síť s částečnou rekurencí.
- Architektura má 4 vrstvy (vstup, skrytá vrstva, kontextová vrstva, výstup). Účelem kontextové vrstvy je si krátkodobě zapamatovat výstupy skryté vrstvy, takže každý neuron skryté vrstvy má svou paměťovou buňku. Tato struktura umožňuje detekci časově-proměnlivých příznaků.
- V roce 1990 se tím Elman snažil predikovat následující slova ve větách.
- Využívá BPTT kde se rekurence rozbalí a počítá se jako klasická dopředná síť.
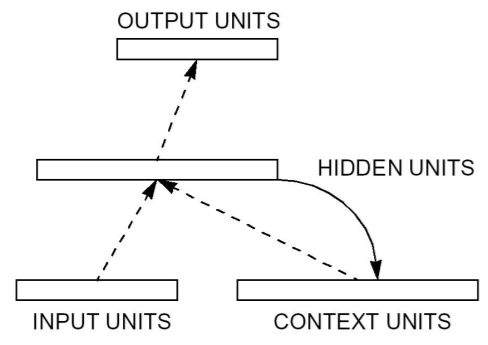
Hopfieldova sit¶
- Skládá se z jedné vrstvy n fully connected rekurentních neuronů, tedy každý neuron je vstupem každého dalšího neuronu kromě sebe samotného (vrstva zároveň slouží jako kontext).
- Content-addressable memory (asociativní paměť), jelikož si do Hopfieldovy sítě lze něco ukládat. Typický příklad je si do sítě uložit jak vypadají nějaká čísla, a pak tam pošleme nějaké trochu poškozené číslo a síť vybaví to správné zapamatované. Asociace znamená, že máme nějaké referenční vzory, které se na ty vstupy vybavují.
- Hebbovské nesupervizované učení – když se dva neurony aktivují společně, tak se mezi nimi posilují synapse (stejně jako v mozku).
- Neurony mají výstupy buď 1 nebo -1.
- Váhy se neučí iterativním způsobem jako bývá zvykem, ale nastavují se v jednom kroku.
- Váhy se inicializují na 0.
- Pro každé dva neurony sečteme násobek jejich výstupů a to bude váha jejich synapse. Když po vstupu mají dva neurony stejný výstup (1 a 1 nebo -1 a -1), tak se jejich váha zvyšuje, jinak se snižuje.
- Hopfieldova síť má velmi omezenou kapacitu (počet různých uložených vzorů odpovídá tak 14 % počtu neuronů v síti).
- Využití při optimalizaci či auto-asociaci (něco jako autoencoding).
Jak se učí?¶
- Elmanova sit - Back Propagation Through Time
- Hopfieldova sit
- Síť lze modelovat jako energetickou funkci, kde se pohybujeme v prostoru chyby sítě. Pro vysoce stabilní stavy (shodující se neurony) jsou vyšší váhy a kvůli zápornému znaménku sumy v energetické funkci tak v prostoru vytváříme dolíky. Naopak nestabilní stavy s nízkými vahami tvoří kopce. Celkovou energii se postupně snažíme minimalizovat. Když vložíme vstup a necháme síť iterovat, tak se postupně stabilizuje energie a sklouzáváme do nejblizšího dolíku, který představuje nějaký uložený vzor. Lokální minima tedy představují uložené vzory, které fungují jako atraktory.
- Snažíme se vzory dělat co nejvíce odlišné, abychom při iteracích nespadly do nějakého podobného lokálního minima když jsou dolíky moc u sebe.
Co jsou echo state networks?¶
Echo state networks (Reservoires)¶
- Skládá ze dvou částí: rezervoáru (nebo také zvaného "echo state") a výstupní vrstvy.
- Je to RNN síť která ma fixní neurony v skryte vrstvě.
- Vnitřní neurony se náhodně neinicializují.
- Při trénovaní se trénuji pouze výstupní neurony
- Používá především pro úlohy zpracování přírodního jazyka a predikce sérií časových dat.
Proč LSTM a GRU?¶
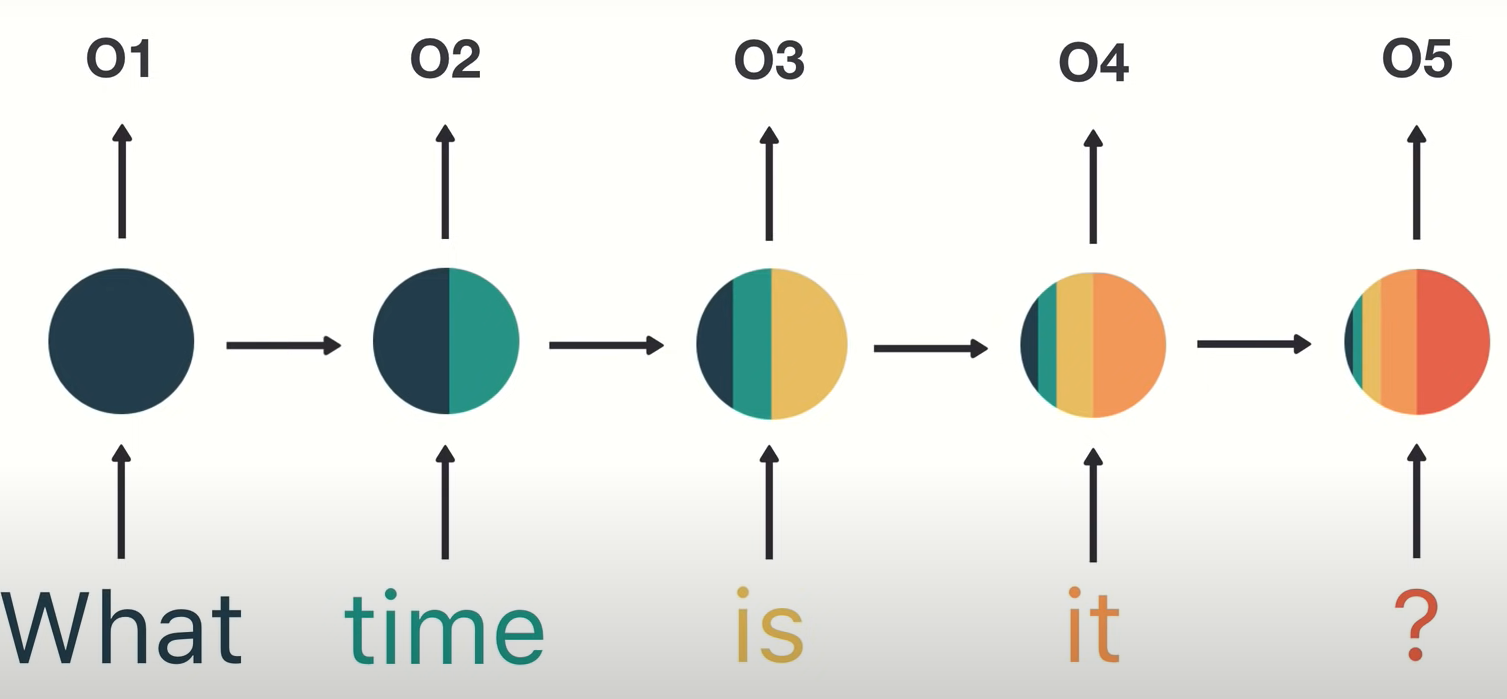 - Na tomto obrázku je znázorněn problém s krátkodobou pamětí rekurentních sítí (short term memory je způsobeno vanishing gradient problémem). Při zpracování vstupů má problém si udržovat informace z dřívějších.
- Kvůli tomuto problému vznikly rekurentní síte LSTM a GRU. Jsou schopny se učit dlohodobější závislosti díky mechanismu hradel (gates). Gaty jsou určité tensor operace, které se učí jaké informace přidávat či odebírat ze skrytého stavu. Pokud se síť naučí, že nějaká informace je důležitá, tak ji může ponechat a přidat v pozdějším kroku.
- Není jasné jestli je lepší LSTM nebo GRU, většinou je potřeba zkusit obojí.
- Čisté RNN jsou tedy rychlejší, vhodné pro krátké sekvence a krátkodobé vztahy.
- Na tomto obrázku je znázorněn problém s krátkodobou pamětí rekurentních sítí (short term memory je způsobeno vanishing gradient problémem). Při zpracování vstupů má problém si udržovat informace z dřívějších.
- Kvůli tomuto problému vznikly rekurentní síte LSTM a GRU. Jsou schopny se učit dlohodobější závislosti díky mechanismu hradel (gates). Gaty jsou určité tensor operace, které se učí jaké informace přidávat či odebírat ze skrytého stavu. Pokud se síť naučí, že nějaká informace je důležitá, tak ji může ponechat a přidat v pozdějším kroku.
- Není jasné jestli je lepší LSTM nebo GRU, většinou je potřeba zkusit obojí.
- Čisté RNN jsou tedy rychlejší, vhodné pro krátké sekvence a krátkodobé vztahy.
LSTM¶
- Síť má schopnost dlouhodobé paměti, která je implementována pomocí vnitřních mechanismů (hradel), které mají kontrolu nad tokem informací.
- Informace z prvnotních časových kroků se může projevit výrazně později.
- Sklada se z:
- Forget gate - Rozhoduje, které informace ponechat a které zahodit.
- Input gate - Určuje které informace ze současného vstupu se budou ukládat do LSTM paměťové buňky.
- Cell state - Stav buňky je buď zapomenut či ponechán podle toho co vyjde z Forget gate sigmoidy (0 nebo 1) pomocí násobení tímto výstupem.
- Output gate - Rozhodne hodnotu následujícího vnitřního stavu.
GRU¶
- Novější RNN, méně parametrů než LSTM.
- Nemá stav buňky, používá vnitřní stav k přenosu informací.
- Update gate
- Rozhoduje jak moc předchozí informace předat do budoucna.
- Jednak co z minulých informací předávat dál a také co ze současného vstupu.
- Reset gate
- Rozhoduje jaké informace už můžeme zapomenout.
Jiné způsoby realizace dlouhodobé paměti?¶
Stack RNN¶
- Alternativní realizace dlouhodobé paměti pomocí externí paměti (zásobník, fronta).
- Elmanova síť kde místo kontextuálních buněk máme zásobník, kam lze informace PUSHovat a naopak odebírat POPem.
- Může být i více paralelních zásobníků.