Snizovani-poctu-prvku #Redukce-dat #KNN #CNN¶
Nearest Neighbor rule¶
- Snaha zachytit vzdálenosti bodů v prostoru
- Tvoří shluky, na jejichž základě je možné “opravit” jedince
- Když prvek predikuje např. Y=0, ale patří do shluku, kde jeho K sousedů tvoří prvky predikující Y=1, tak se prvek upraví
- Drahé na výpočet, paměť a problémy s dimenzionalitou
- Nejčastěji se používají Minkowského metriky
Přístupy ke snižování počtu prvků¶
Condensing¶
- Decision Boundary Consistent
- Z dat vezme podmnožinu, jejíchž shluky budou vytvářet stejné hranice rozdělení bodů v prostoru
- Minimum Consistent Set
- Nejmenší možná podmnožina, které umožňuje správně klasifikovat všechna původní data
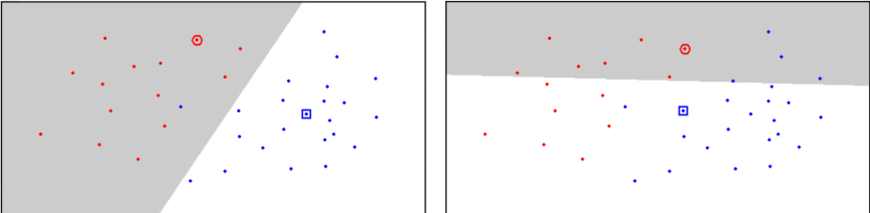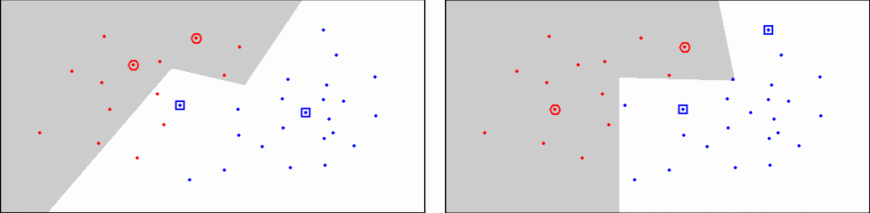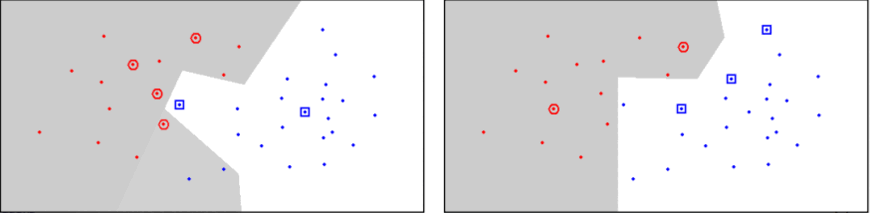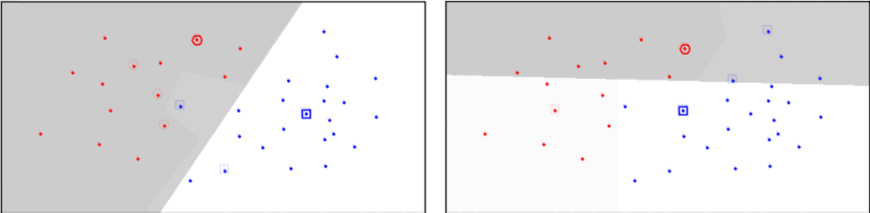
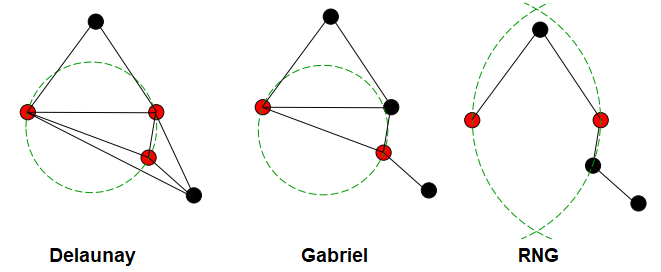
Delaunay Triangulation¶
- 3 body jsou považovány za sousedy, pokud kružnice, která má tyto 3 body na sobě, neobsahuje žádné jiné body
- Voronoi editing využívá tohoto principu
- Nechá v datasetu pouze body ze shluků, ve kterých jsou sousedé (definování např. Delaunayovou triangulací) body patřící do jiných tříd
- Ponechává body na hranici
Gabriel¶
- Podmnožina Delaunay Triangulation
- Kružnice tvořeny pouze 2 body,
- neumožňuje bod uvnitř kruhu
- Méně náročné na výpočet oproti Delaunayovi
RNG¶
- Používá “lune” namísto kružnice
- Není zaručeno, že je training set consistent
Delaunay x Gabriel x RNG¶
Redukce dat¶
- Snaží se odebrat body šumu z dat
Wilson Editing¶
- Odebrání bodů jež se neshodují s majoritou z jejich K nejbližších sousedů
Multi-edit¶
- Opakovaná aplikace Wilson Editing na random subsety
- Klasifikuje vzor podle 1-NN pravidla
Algoritmy redukce poctu dat¶
Selektivní¶
CNN¶
- Vybírá prvky, které jsou poblíž hranice mezi shluky
- Může přidávat redundantní prvky
- Inkrementální algoritmus
RNN¶
- Výstup z CNN je dále redukován (iteračně zkouší odebrat prvek po prvku a následně je do vybrané podmnožiny vrací na základě zhoršení/zlepšení kvality predikce)
IB3¶
- Podobný přístup jako CNN, ale vybírá prvky na základě statistického testování
- Může mít redundantní instance
DROP3¶
- Postupné odebírání prvků, pokud jejich smazání nemění/neovlivní klasifikaci
- Klasifikace se provádí pomoci KNN
Adaptivní¶
Prototype¶
- Snaží se spojit páry bodů, které jsou k sobě nejblíže tím, že je “zmerguje” a výsledný 1 bod bude v prostoru mezi původními 2 body
Chen¶
- Umožňuje nastavit požadovanou velikost výsledné podmnožiny, nové body jsou těžiště originálních dat (shluků dat)
RSP1¶
- Podobny přístup jako Chen ale ještě přidává class balancing