2. Úvod do OpenMP
5. OpenMP: programový model, paralelní region, vlastnosti proměnných¶
Fork-join model¶
- OpenMP je explicitní model paralelního výpočtu, kdy má programátor plnou kontrolu a zodpovědnost za paralelní výpočet.
- Ve vybraných částech původně sekvenčního kódu, zvaných paralelní regiony (parallel regions), jsou pomocí fork-join mechanismu vytvářena, prováděna a ukončována paralelní vlákna.
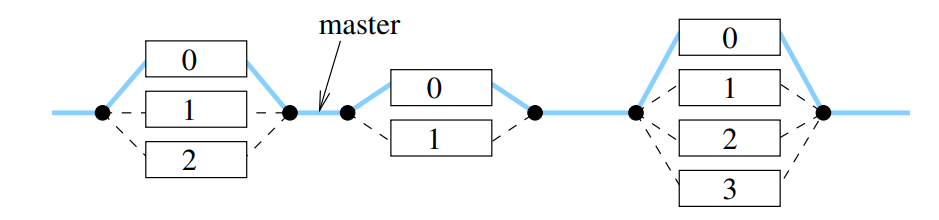
- Mimo paralelní regiony existuje pouze 1 hlavní (master) vlákno.
- OpenMP zahrnuje podporu pro iterační i funkční model paralelismu.
- OpenMP implementace může využívat zásobárnu recyklovatelných vláken (thread pool) pro snížení režie vytváření/ukončování vláken.
Paralelní region¶
- Paralelní region je kód, který je určen k vykonávání více vlákny současně.
- Vytvoří se pomocí direktivy
#pragma omp parallel. - Kód paralelního regionu je naklonován pro všechna vlákna, která ho začnou provádět.
- Na konci paralelního regionu je implicitní bariéra. Po jejím provedení jsou nově vzniklá vlákna ukončena (případně uložena do thread pool) a dále pokračuje jen hlavní vlákno 0.
- Pokud je z nějakého důvodu během paralelního regionu jedno z vláken předčasně ukončeno, jsou předčasně ukončena všechna vlákna a tím i celý program.
Možné klauzule direktivy:
if (podminka): podmínka paralelizace regionu.num_threads(vyraz): počet vláken v paralelním regionu.
Vlastnosti proměnných v paralelním regionu:¶
Shared¶
- Proměnná je sdílená mezi všemi vlákny a existuje jen jedna instance. Všechna vlákna vidí a mají přístup ke stejné paměti.
Private¶
- Každé vlákno má svou vlastní kopii proměnné. Modifikace této proměnné jsou viditelné pouze uvnitř daného vlákna.
Firstprivate¶
- Podobné jako
private, ale každé vlákno dostane počáteční hodnotu proměnné z vlákna, které vstoupilo do paralelního regionu. To znamená, že každé vlákno začíná s hodnotou, kterou měla proměnná na začátku paralelního regionu.
Lastprivate¶
- Opět podobné jako
private, ale hodnota proměnné z poslední iterace cyklu se nakopíruje zpět do původní proměnné po ukončení paralelního regionu.
Threadprivate¶
- Proměnná je
privatenapříč více paralelními regiony pro každé vlákno. To znamená, že hodnota proměnné zůstane zachována mezi různými paralelními regiony uvnitř stejného vlákna.
Default¶
- Umožňuje specifikovat výchozí vlastnost proměnných, které nejsou explicitně uvedeny v klausulích jako
private,sharedatd. Může být nastaveno nanone(vyžaduje explicitní specifikaci pro všechny proměnné),shared(všechny proměnné jsou implicitněshared), neboprivate(všechny proměnné jsou implicitněprivate).
Reduction¶
- Umožňuje kombinovat hodnoty mezi vlákny do jedné hodnoty (např. součet, maximum) po ukončení paralelního regionu. Každé vlákno pracuje s vlastní lokální kopií proměnné během paralelního výpočtu, a poté jsou tyto lokální kopie kombinovány do jedné globální hodnoty.
6. OpenMP: datový paralelismus (direktiva for), sémantika, parametry¶
Datový paralelismus v OpenMP znamená, že stejný kód je vykonáván současně na různých částech datové struktury. V praxi se jedná často o paralelizaci cyklů, které zpracovávají prvky pole nebo jiné datové struktury.
Direktiva for¶
- Direktiva pro přidělení jednotlivých iterací
forcyklu uvnitř paralelního regionu jednotlivým vláknům. - Předpokládejme n iterací a p vláken.
- Na konci paralelního cyklu je implicitně bariéra.
- Direktiva musí být použita uvnitř paralelního regionu, což můžete zajistit kombinací direktiv
#pragma omp parallela#pragma omp for, nebo je můžete kombinovat do jedné direktivy#pragma omp parallel for.
Příklad použití:
#pragma omp parallel for schedule(dynamic, 10) collapse(2)
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
// ... zpracování dat
}
}
Parametry¶
Parametry mohou být kombinovány, aby se dosáhlo požadovaného chování paralelního cyklu.
1. schedule¶
Parametr schedule umožňuje ovlivnit, jak jsou iterace cyklu rozděleny mezi vlákna. Existuje několik možností pro strategii rozdělení:
static- Iterace cyklu jsou rozděleny do bloků pevné velikosti. Pokud není velikost bloku specifikována, OpenMP ji rovnoměrně rozdělí mezi vlákna.
dynamic- Iterace cyklu jsou rozděleny do bloků, ale vlákna si dynamicky berou bloky, jakmile dokončí své předchozí bloky. Toto rozdělení je užitečné, pokud jsou některé iterace výpočetně náročnější než jiné.
guided- Podobně jako dynamické rozdělení, ale velikost bloků se postupně snižuje, takže pozdější bloky jsou menší. To může pomoci vyvážit zatížení mezi vlákny.
auto- OpenMP rozhoduje o strategii rozdělení iterací. Uživatel nemá přímou kontrolu nad tím, jak je rozdělení provedeno.
runtime- Rozdělení iterací je určeno v době spuštění programu pomocí nastavení environmentální proměnné
OMP_SCHEDULEnebo voláním rutinyomp_set_schedule().
- Rozdělení iterací je určeno v době spuštění programu pomocí nastavení environmentální proměnné
2. collapse(n)¶
- Tento parametr umožňuje paralelizovat více vnořených cyklů. Hodnota
nudává počet vnořených cyklů, které mají být sloučeny do jednoho. - Například
collapse(2)znamená, že OpenMP spojí první a druhý cyklus do jediného, který bude paralelizován.
3. ordered¶
- Umožňuje, aby část kódu uvnitř cyklu byla provedena v pořadí definovaném iteracemi cyklu, jako by to bylo při sekvenčním vykonávání.
- Je to užitečné, když potřebujete udržet určité pořadí operací v rámci paralelního cyklu.
4. nowait¶
- V OpenMP, po dokončení paralelního cyklu, existuje implicitní bariéra, která zajišťuje, že žádné vlákno nepokračuje, dokud všechna vlákna nedokončí cyklus.
- S parametrem
nowaitmůžete potlačit tuto implicitní bariéru, což umožňuje vláknům pokračovat ihned po dokončení svých iterací cyklu.
7. OpenMP: funkční paralelismus (direktiva task), sémantika, parametry¶
Funkční paralelismus v OpenMP znamená vykonávání různých částí kódu paralelně. Tento přístup je odlišný od datového paralelismu, kde se stejný kód vykonává na různých částech dat. U funkčního paralelismu může být každá úloha (task) odlišná a může být vykonávána paralelně s jinými úlohami. Toho lze dosáhnout pomocí direktivy task.
Funkční paralelismus¶
- Jiný název je task paralelismus
- Používáno převážně u rekurzivních algoritmů: rozděl a panuj
- Mechanismus přidělování úloh v OpenMP je založen na modelu producent-konzument.
Task¶
Úloha je jednotka paralelního výpočtu, která obsahuje:
-
Ukazatel na začátek kódu: Odkaz na konkrétní část kódu, která má být vykonána.
-
Vstupní data: Data, která jsou nutná pro vykonání daného kódu.
-
Datová struktura s identifikátorem vlákna: Když vlákno začne vykonávat úlohu jako konzument, vloží svůj identifikátor do této datové struktury. Toto vlákno se následně nazývá "vlastnické vlákno".
Direktiva task¶
Direktiva task v OpenMP se používá k označení bloku kódu, který má být vykonáván jako samostatná úloha. Úlohy jsou nezávislé a mohou být vykonávány paralelně s ostatními úlohami nebo hlavním vláknem.
Příklad použití:
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task
{
// kód první úlohy
}
#pragma omp task
{
// kód druhé úlohy
}
#pragma omp taskwait
}
}
Provedení Direktivy #pragma omp task¶
Provedení direktivy #pragma omp task v OpenMP má následující účinky:
-
Vlákno-producent: Vlákno, které vykonává kód s touto direktivou, vygeneruje novou úlohu a vloží ji do tzv. zásobárny úloh (anglicky "task pool").
-
Čekání na zpracování: V zásobárně úloh, úloha čeká, dokud si ji některé volné vlákno-konzument nevyzvedne a nezačne ji provádět.
Sémantika¶
- Direktiva
taskmusí být uvnitř paralelního regionu. - Konec úlohy je implicitně nesynchronizovaný, což znamená, že vlákno, které vytvořilo úlohu, může pokračovat dál, aniž by čekalo na dokončení úlohy.
- Direktiva
#pragma omp taskwaitzpůsobí, že úloha v roli rodičovské čeká na dokončení všech synovských úloh (= pouze přímých potomků). - Direktiva
singleje použita k tomu, aby zajistila, že blok kódu uvnitř této direktivy bude proveden pouze jedním vláknem. To je užitečné pro inicializaci task paralelismu tak aby se zabránilo jeho zahájení vícekrát
Parametry direktivy task¶
-
if(scalar_expression): Pokud je výraz pravdivý, je vytvořena nová úloha. Je-li nepravdivý, kód je vykonán sekvenčně vláknem, které na tomto místě přišlo. -
final(scalar_expression): Je-li výraz pravdivý, úloha je vytvořena jako konečná a žádné další vnořené úlohy uvnitř nebudou paralelizováný.
8. OpenMP: synchronizační direktivy¶
#pragma omp barrier: Čeká, dokud nejsou všechna vlákna hotova.#pragma omp single: Daný blok kódu smí provést pouze jedno libovolné vlákno, ostatní daný blok kódu přeskočí.#pragma omp master: Daný blok kódu smí provést pouze hlavní vlákno, ostatní daný blok kódu přeskočí.#pragma omp critical: Zajišťuje, že následující blok kódu bude vykonán v jednom okamžiku pouze jedním vláknem současně.#pragma omp ordered: Zajišťuje, že blok kódu uvnitř cyklu je proveden ve stejném pořadí jako iterace cyklu.#pragma omp flush: Zajišťuje, že aktuální hodnoty sdílených proměnných jsou propisovány z lokálních pamětí do sdílené paměti.#pragma omp taskwait: Zajišťuje synchronizaci mezi parent úlohami a child úlohami v task paralelismu.#pragma omp cancel: Poskytuje snadný a bezpečný způsob předčasného ukončení paralelního regionu- Vlákno provedením
cancelvydá pro ostatní vlákna signál k ukončení výpočtu a přejde na závěrečnou bariéru a čeká na ostatní. - Ostatní vlákna se ukončí až v okamžiku, kdy narazí na operaci
cancel. Pokud ostatní vlákna už nenarazí na operacicancel, dokončí svůj kód v paralelním regionu.
- Vlákno provedením
#pragma omp atomic: Zajišťuje, že specifická paměťová operace je provedena atomicky.- Operace atomic nelze aplikovat na dvě místa ve sdílené paměti najednou.
- read
- write
- update - Read-Modify-Write
- capture - rozšiřuje operaci update o získání hodnoty dané proměnné před nebo po provedení Modify části. Důležité využití této funkcionality je např. při dynamickém přidělování pracovního prostoru vláknům.