SVM Regrese
6. Jádrová regrese - Lineární expanze do bázových funkcí, duální formulace, jádrový trik
7. Jádrové funkce - Souvislost s bázovými funkcemi, obecné vlastnosti, příklady
8. Support Vector Machines - Lineárně separabilní a neseparabilní případ, diskuse řešení
SVM regrese - prvotní formulace pomocí vázaných extrémů¶
Úvod¶
Support Vector Machines (SVM) regrese je metoda založená na principu SVM, která je primárně určena pro klasifikaci. V kontextu regrese se SVM používá k modelování vztahu mezi závislou a nezávislou proměnnou.
Definice¶
Základní model vztahu mezi závislou proměnnou Y a nezávislým vektorem příznaků X lze vyjádřit jako:
kde X = (X_1, \ldots, X_p)^T je náhodný vektor příznaků, \phi = (\phi_1, \ldots, \phi_M)^T je vektor bázových funkcí, w = (w_1, \ldots, w_M)^T je vektor neznámých koeficientů, w_0 je neznámý koeficient zvaný intercept a \varepsilon je náhodná veličina s E\varepsilon = 0.
Bázové funkce \phi_j, j=1,\ldots,M umožňují představit lineární vztah v transformovaném prostoru příznaků, který může být nelineární v původním prostoru příznaků. Můžeme použít různé typy bázových funkcí, včetně polynomiálních, gaussovských a dalších.
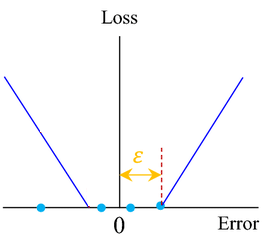
ε necitlivá ztrátová funkce¶
V rámci SVM regrese se používá specifická ztrátová funkce L_{\varepsilon}, známá jako \varepsilon-necitlivá ztrátová funkce, definovaná následovně:
Tato funkce nabízí robustní odhad chyby pro hodnoty v rozmezí \varepsilon, kde |Y - \hat{Y}| \leq \varepsilon.
Minimalizovana funkce¶
Cílem je minimalizovat funkci J, která je definována následovně:
kde C = 1/(2\lambda) je konstanta a L je \varepsilon-necitlivá ztrátová funkce.
Reformulace pomocí vázaného extrému¶
Vzhledem k výběru ztrátové funkce je proces minimalizace komplikovaný, protože J_{\varepsilon} není všude diferencovatelná podle složek w. Proto se problém řeší pomocí reformulace do problému vázaného extrému.
Volné (slack) proměnné¶
Pro každý bod trénovací množiny se definují dvě volné proměnné \xi_i^+ a \xi_i^-, které mají tyto vlastnosti:
- Obe dvě jsou nezáporné: \xi_i^+ \ge 0 \ \ \ \ \xi_i^- \ge 0,
- \xi_i^+ \ge Y_i − \hat{Y}_i − \varepsilon,
- \xi_i^- \ge \hat{Y}_i - Y_i − \varepsilon.
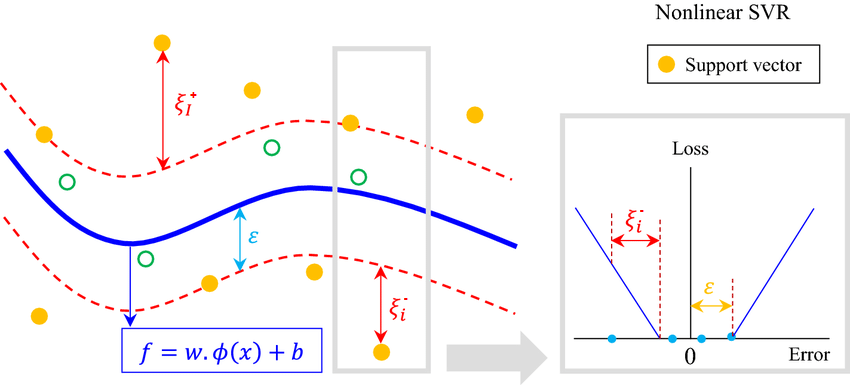
Z čehož plyne: L_\varepsilon(Y_i, \hat{Y}_i) \leq \xi^{+}_i + \xi^{-}_i
Nová minimalizující funkce¶
Využitím volných proměnných \xi_i^+ a \xi_i^- můžeme reformulovat funkci J takto:
Tímto je problém přeformulován na konvexní optimalizační úlohu, kterou lze efektivně řešit pomocí dostupných optimalizačních algoritmů.
SVM regrese - duální přístup a vlastnosti řešení¶
Duální formulace¶
Minimalizace tohoto vázaného extrému se nejčastěji řeší duální reformulací. Vytváříme odpovídající Lagrangeovu funkci L závislou na proměnných a také na Lagrangeových multiplikátorech.
Definice: Lagrangeova funkce¶
Označme nove multiplikátory:
- \mu^+_i \ \ \Rightarrow \ \ \xi_i^+ \ge 0
- \mu^-_i \ \ \Rightarrow \ \ \xi_i^- \ge 0
- \alpha^+_i \ \ \Rightarrow \ \ \xi_i^+ \ge Y_i − \hat{Y}_i − \varepsilon
- \alpha^-_i \ \ \Rightarrow \ \ \xi_i^- \ge \hat{Y}_i - Y_i − \varepsilon
Potom definujeme Lagrangeovu funkci L jako:
Pro bod ve kterém se nachází minimum L platí: - Gradient je rovny nule: Lze snadno ukázat, že v našem případě jsou splněny Slaterovy podmínky a platí tedy silná duálnost. Z toho plyne, že primární a duální problém mají stejné optimální hodnoty a že jsou splněny KKT podmínky to znamená ze:
Duální problém¶
Duální problém je maximalizace Lagrangeovy funkce L při splnění podmínek \mu_i^+ \geq 0, \ \ \mu_i^- \geq 0 a \alpha_i^+ \geq 0,\ \ \alpha_i^- \geq 0. Z rovnice \nabla_{\hat{w}_0,\hat{w},\hat{\xi}_+,\hat{\xi}_-} L = 0 dostáváme pro ideální hodnoty w_0, w, \xi_+, a \xi_- následující rovnice (neboli postupně parciálně zderivujeme podle w_0, w, \xi_+, a \xi_- ):
Dosazením rovnic do Lagrangeovy funkce L dostáváme duální problém jako:
Který je potřeba maximalizovat. Při splnění podmínek:
Vlastnosti řešení¶
Představení řešení¶
Řešení SVM regresní úlohy není možné nalézt explicitně. Jedná se ale o standardní úlohu kvadratického programování, která je numericky dobře řešitelná. Označíme-li řešení této úlohy jako \hat{\alpha_i}^+ a \hat{\alpha_i}^-, platí tedy:
Vyjádření w¶
Máme-li \hat{\alpha_i}^+ a \hat{\alpha_i}^- můžeme vyjádřit \hat{w} pomocí vztahu:
Predikce¶
Pro predikci \hat{Y}_0 hodnoty Y_0 v bodě x_0 tak platí:
Spolu s definicí jádrové funkce tak dostáváme finální vyjádření v termínech \hat{\alpha_i}^+, \hat{\alpha_i}^- a \hat{w}_0:
což tvoří analogii k jádrovému modelu, kde \alpha_i = (\alpha^+_i + \alpha^-_i).
Možné hodnoty \hat{\alpha_i}^+ a \hat{\alpha}^-¶
Podle KKT podmínek jsou možné následující hodnoty:
-
\hat{\alpha}^+_i = \hat{\alpha}^-_i = 0: Tento případ odpovídá situaci, kdy bod x_i leží uvnitř \varepsilon pásmu. To znamená, že se bod Y_i nachází mezi \hat{Y}_i - \varepsilon a \hat{Y}_i + \varepsilon.
-
0 < \hat{\alpha}^+_i < C a \hat{\alpha}^-_i = 0: Tento případ odpovídá situaci, kdy bod x_i leží nad horním okrajem \varepsilon pásmu, tj. Y_i > \hat{Y}_i + \varepsilon.
-
\hat{\alpha}^+_i = 0 a 0 < \hat{\alpha}^-_i < C: Tento případ odpovídá situaci, kdy bod x_i leží pod spodním okrajem \varepsilon pásmu, tj. Y_i < \hat{Y}_i - \varepsilon.
-
\hat{\alpha}^+_i = C a \hat{\alpha}^-_i = 0: Tento případ odpovídá situaci, kdy bod x_i leží na horním okrajem \varepsilon pásmu, tj. Y_i = \hat{Y}_i + \varepsilon.
-
\hat{\alpha}^+_i = 0 a \hat{\alpha}^-_i = C: Tento případ odpovídá situaci, kdy bod x_i leží na spodním okrajem \varepsilon pásmu, tj. Y_i = \hat{Y}_i - \varepsilon.
Tedy buď jsou oba koeficienty \hat{\alpha}^+_i a \hat{\alpha}^-_i nulové, nebo je pouze jeden z nich nenulový. Body x_i, pro které je jeden z koeficientů \hat{\alpha}^+_i a \hat{\alpha}^-_i nenulový, se nazývají nosné body případně support vectors.
Určení \hat{w}_0¶
Pokud existuje takové i = 1, . . . , N, že 0 < \hat{\alpha}^+_i < C nebo 0 < \hat{\alpha}^-_i < C, můžeme určit \hat{w}_0 podle případu:
- Pokud 0 < \hat{\alpha}^+_i < C:
- Pokud 0 < \hat{\alpha}^-_i < C:
Pokud takové i neexistuje, \hat{w}_0 není jednoznačně určeno a může být zvoleno libovolně v rámci omezení, které znamenají:
- pro \hat{\alpha}^+_i = 0: \hat{w}_0 \ge Y_i - \sum_{j=1}^{N} (\hat{\alpha}^+_j - \hat{\alpha}^-_j) K(x_i, x_j) - \varepsilon
- pro \hat{\alpha}^-_i = 0: \hat{w}_0 \le Y_i - \sum_{j=1}^{N} (\hat{\alpha}^+_j - \hat{\alpha}^-_j) K(x_i, x_j) + \varepsilon
- pro \hat{\alpha}^+_i = C: \hat{w}_0 \le Y_i - \sum_{j=1}^{N} (\hat{\alpha}^+_j - \hat{\alpha}^-_j) K(x_i, x_j) - \varepsilon
- pro \hat{\alpha}^-_i = C: \hat{w}_0 \ge Y_i - \sum_{j=1}^{N} (\hat{\alpha}^+_j - \hat{\alpha}^-_j) K(x_i, x_j) + \varepsilon