1 Similarity based Methods
Understanding Recommendations¶
Recommender systems are designed to suggest items to users based on various factors. These systems generally tackle two types of learning problems:
-
Predictive Modeling: This method aims to predict how much a user would like a specific item. For example, it tries to forecast if a user will rate a movie highly or not. Predictive modeling makes these predictions based on the user's past behavior or ratings.
-
Retrieval Modeling: In contrast to predictive modeling, retrieval modeling focuses on ranking preferences. Instead of predicting exact ratings, it sorts items according to how likely a user is to prefer one item over another. For instance, it might determine whether a user is more likely to enjoy one book over another, without necessarily predicting the exact ratings for either book.
Both models use a combination of user interactions and attributes:
-
Interactions:
- Explicit Feedback: This is direct feedback from users, like giving a movie a specific rating out of 10.
- Implicit Feedback: This type of feedback is indirect, inferred from user actions, such as how much of a video a user watches or how often they play a song.
-
Attributes:
- User Attributes: These include demographic information about the users, such as age, gender, and location.
- Item Attributes: These are characteristics of the items being recommended, like the genre of a book or the director of a movie.
Types of Recommendations¶
Recommender systems can vary in their approach:
-
Items to Users: Recommending a specific product to a user, like suggesting a new book to a reader based on their reading history.
-
Users to Items: Suggesting a target audience for a product, like identifying potential buyers for a newly released smartphone.
-
Items to Items: Recommending similar items, like suggesting movies similar to one a user just watched.
-
Users to Users: Connecting users with similar interests, such as suggesting a new friend in a social network based on shared hobbies.
Modeling Implicit and Explicit Feedback¶
In recommender systems, understanding user preferences can be achieved through two types of feedback: implicit and explicit.
Explicit Feedback¶
This is direct input from users, such as ratings, reviews, or likes.
- Advantages: It's clear and straightforward, representing the user's preferences directly.
- Disadvantages: It can be sparse, as not all users take the time to rate or review items. Also, it may be biased, as users who provide feedback might not be representative of the entire user base.
Implicit Feedback¶
This type is inferred from user actions like browsing history, purchase records, or time spent on an item.
- Advantages: It's abundant and continuously generated as users interact with items.
- Disadvantages: It's less clear, as actions like page views don’t always indicate preference. Also, it's harder to interpret, as the same action might mean different things for different users or items.
Collaborative Filtering vs Content-Based Filtering¶
Recommender systems generally use one of two approaches: collaborative filtering or content-based filtering.
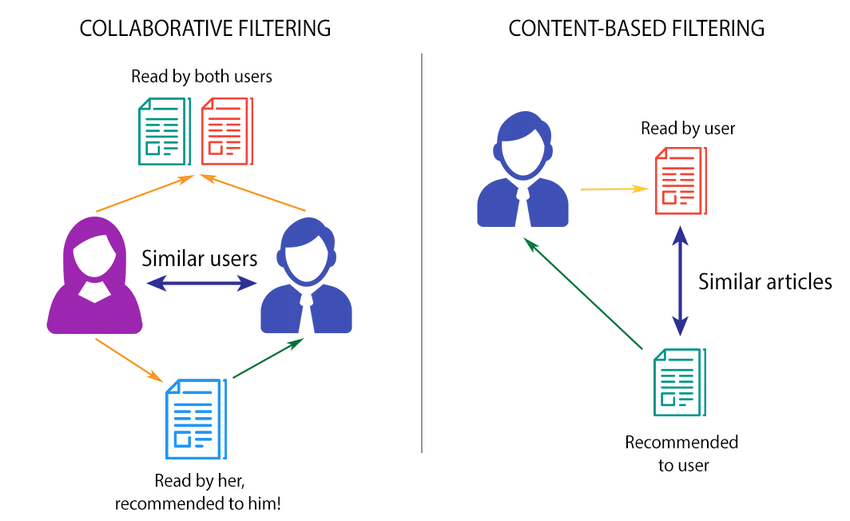
Collaborative Filtering¶
This method makes recommendations based on the preferences of similar users. For instance, if User A and User B liked many of the same movies, then a movie liked by User A but not seen by User B might be recommended to User B.
- Advantages: It doesn't require item metadata and can recommend unexpected items outside a user's typical preferences.
- Disadvantages: It suffers from the cold-start problem (hard to recommend for new users or items) and can be less effective when data is sparse.
Content-Based Filtering¶
This approach recommends items similar to those a user liked in the past, based on item features like genre, director, or actor in the case of movies.
- Advantages: It's more straightforward to implement and doesn’t require data about other users.
- Disadvantages: It tends to recommend items very similar to what the user already knows and might miss out on serendipitous recommendations.
Understanding Similarity in Recommender Systems¶
Similarity is a fundamental concept in recommender systems, determining how closely related items or users are to each other.
-
What is Similarity?
- In the context of recommender systems, similarity measures how alike two items or users are. For example, two movies might be considered similar if they belong to the same genre or have similar ratings from users.
-
How is Similarity Used?
- Similarity is used to make recommendations. If a user likes a particular item, the system can recommend other similar items. Similarly, if two users have similar tastes, the system can recommend items liked by one user to the other.
-
Bases of Similarity:
- User/Item Attributes: This involves comparing the characteristics of items (like genre or director of a movie) or users (like age or location). For example, if two users are of similar age and live in the same city, they might have similar preferences.
- User-Item Interactions: This approach looks at how users interact with items. For instance, if two users have rated many of the same movies highly, they are considered similar. This can also involve looking at patterns like purchase history or viewing behavior.
Similarity Methods¶
In recommender systems, various methods are used to calculate similarity. Here are some key approaches:
k-NN (k-Nearest Neighbors) Algorithm for Recommendation¶
- k-NN finds the 'k' closest items or users to a given user or item. For example, identifying the 'k' movies most similar to a specific movie based on user ratings. It's effective in both collaborative and content-based filtering, particularly with a rich dataset of user-item interactions.
Weighted k-NN Algorithm¶
- An extension of k-NN, Weighted k-NN assigns different weights to the 'k-nearest neighbors' based on their distance. This enhances the basic k-NN by considering varying degrees of similarity among the nearest neighbors, leading to more accurate recommendations.
Jaccard Similarity¶
- Jaccard Similarity measures the similarity between two sets, calculated as:
- Commonly used for binary attributes, like determining if a user has purchased an item or not.
Cosine Similarity¶
- Measures the cosine of the angle between two vectors in a multi-dimensional space:
- Widely used in collaborative filtering, particularly effective with sparse data.
Euclidean Similarity¶
- Based on Euclidean distance, this method calculates the 'straight-line' distance between two points:
- Often used with dense data but can be less effective in high-dimensional spaces due to the 'curse of dimensionality'.
Explicit Feedback¶
- Involves using direct user feedback, such as ratings, in calculating similarity. Useful for incorporating clear user preferences but relies on the availability of explicit feedback.