3 Autoencoders for Collaborative Filtering
Autoencoder¶
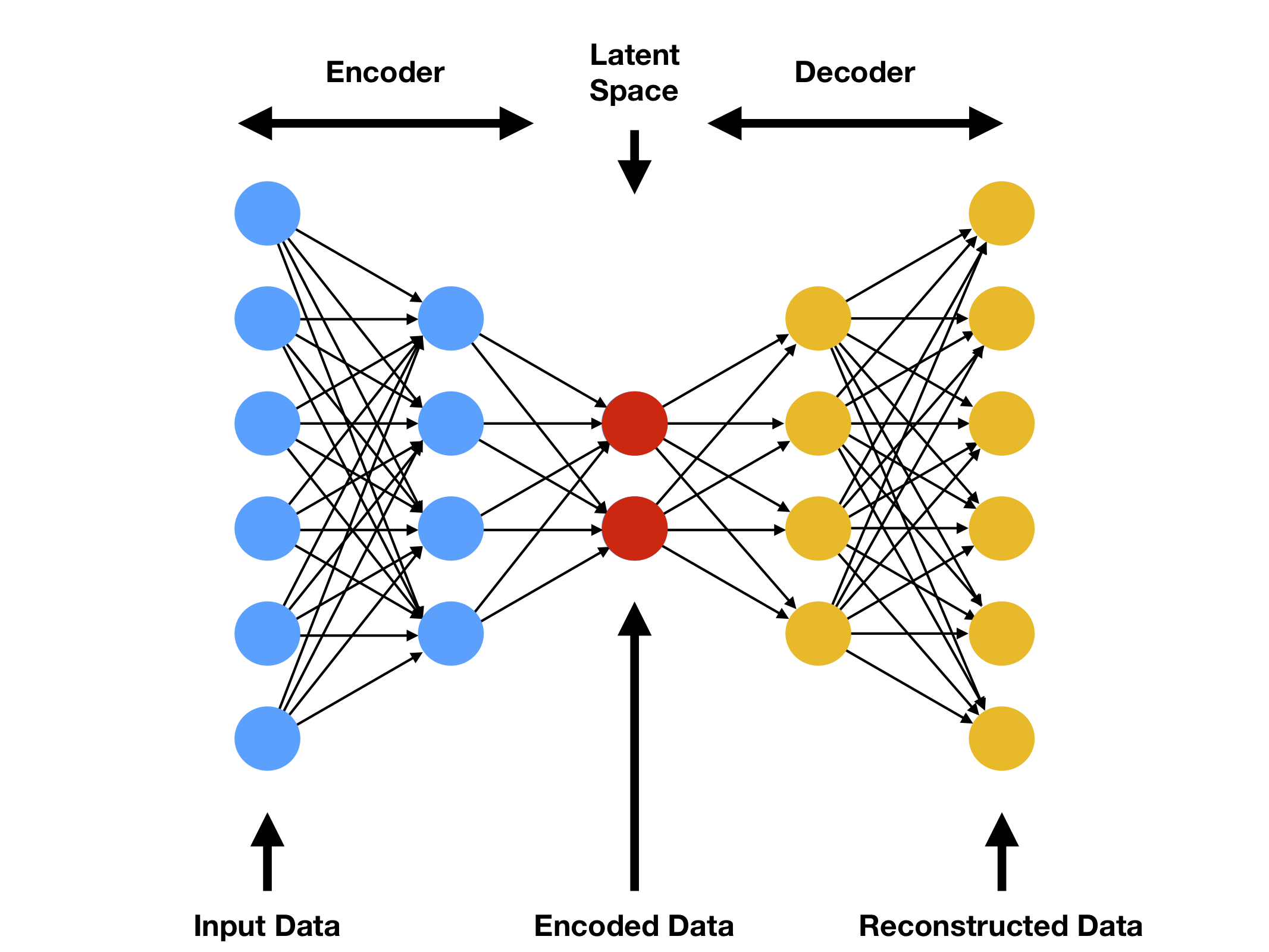
An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled data. The network architecture comprises two main parts: an encoder and a decoder.
- Encoder: This part of the autoencoder compresses the input into a latent-space representation. It encodes the input data as a compressed representation in a reduced dimension.
- Decoder: The decoder then reconstructs the input data from this latent representation, attempting to match the original input as closely as possible.
Autoencoders are trained to minimize the difference between the original input and its reconstruction, thus learning to capture the most important features in the data.
Mathematical Foundation of Autoencoders¶
The key principle behind an autoencoder is to learn a representation (encoding) for a set of data, typically for the purpose of dimensionality reduction. The underlying mathematics can be described through its loss function.
- Loss Function: Consider E(x) as the encoder and D(x) as the decoder. The objective of an autoencoder is to minimize the reconstruction error, which is often measured by a function such as the mean squared error:
- This loss function quantifies the difference between the original input x_i and its reconstruction D(E(x_i)), driving the network to learn efficient encodings.
Autoencoder in Collaborative Filtering¶
Autoencoders, due to their unique structure and learning process, are particularly well-suited for collaborative filtering in recommender systems. They offer a novel approach to capturing and predicting user preferences based on their interactions with items.
Leveraging User Interactions¶
In collaborative filtering, the input to an autoencoder typically consists of user interaction data, such as ratings or views. This data is represented in a way where:
-
Observed interactions (like ratings) are input as their true values.
-
Unobserved interactions (where a user has not rated or interacted with an item) are input as zeros or another special value indicating absence of interaction.
Training the Autoencoder¶
The autoencoder learns to reconstruct these input vectors. However, the key aspect in collaborative filtering is how the autoencoder treats the unobserved values:
-
During training, the autoencoder learns the subtle differences and patterns in user behavior. Even though unobserved interactions are initially marked with a 'zero' or similar value, the network learns to assign them nuanced values based on learned patterns of user preferences and item similarities.
-
The output of the autoencoder, therefore, transforms these 'zero' values into meaningful predictions. For instance, an unobserved value might change from '0' to '0.004' or '0.03', indicating the predicted level of interest a user might have in those items.
Predicting Unobserved Interactions¶
The transformed values in the output layer of the autoencoder are key in collaborative filtering:
-
The larger values among the previously unobserved interactions are interpreted as stronger recommendations. These values indicate items that the user is likely to be interested in, based on the learned patterns of preferences and behaviors.
-
This approach allows the system to prioritize and recommend items that were not previously rated by the user but are likely to be of interest, thus personalizing the user experience.
Advantages in Collaborative Filtering¶
- Non-linear Pattern Recognition: Autoencoders can capture complex, non-linear relationships in user-item interaction data, which might be missed by linear methods like PCA.
- Handling Sparse Data: They are particularly effective in dealing with sparse datasets, a common challenge in recommender systems.
- Scalability and Flexibility: Autoencoders can be scaled to handle large datasets and can be adapted for different types of user-item interaction data.
EASE: Embarrassingly Shallow Autoencoder¶
EASE represents a simplified approach to autoencoders, specifically designed for use in collaborative filtering for recommender systems.
Structure of EASE¶
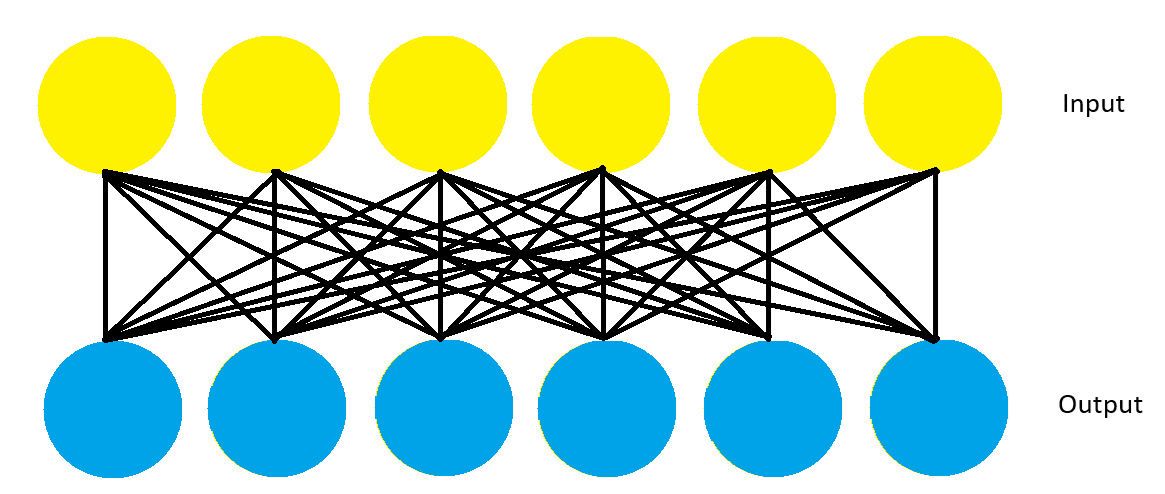
EASE is characterized by a shallow structure, often consisting of a single layer. This contrasts with deep autoencoders that have multiple layers.
- Single Layer: The use of just one layer reduces complexity and speeds up the training and prediction process.
- Focus on Item Representations: EASE directly learns item representations in a lower-dimensional space, aiming to capture essential aspects of user-item interactions.
Functioning of EASE in Collaborative Filtering¶
EASE operates by transforming user interaction data:
- Input: Users' interactions with items are fed into the model, where known interactions have their actual values, and unknown interactions are marked with zeros.
- Output: The model outputs a transformed version of the input. In this output, unobserved interactions are assigned new values, indicating predicted levels of user interest.
Advantages of Using EASE¶
- Efficiency: Due to its simplicity, EASE is efficient in training and prediction, suitable for large datasets.
- Reduced Overfitting Risk: The shallow architecture lessens the risk of overfitting, a common issue in more complex models.
- Handling Sparse Data: EASE is effective for sparse datasets, typical in many recommender systems.