10. Transformery, pozornostní mechanismy, transfer a meta learning. (NI-MVI)¶
Pozornostní mechanismy a Transformery¶
Pozornostních mechanismů¶
Základní myšlenka:
- Model se učí dynamicky zaměřovat na relevantní části vstupních dat při generování výstupu.
- Jednotlivá slova mají přidaný časový vektor, který kóduje jejich pozici ve vstupu
Self-attention (Pozornost uvnitř sekvence)¶
Princip:
- Každý prvek v sekvenci se (např. slovo) porovná se všemi ostatními prvky a určí, jak moc je pro něj každý z nich důležitý.
- Algoritmus:
- Vytvoření embedingů: Každé slovo se zakóduje do latentního prostoru. A spolu s tím se zakóduje i poradí slov.
- Vytvoření vektorů: Každé slovo se vynásobí nějakou matici vah která transformuje embedding:
- Query (Q)
- Key (K)
- Value (V)
- Výpočet vah: Pro každý pár slov (A, B) se spočítá podobnost mezi Q slova A a K slova B.
- Vážený součet: Výstup pro slovo A je kombinace Values všech slov, vážená podle vypočtených podobností.
Proč je užitečná:
- Zachycuje dlouhé závislosti (např. vztah mezi podmětem a přísudkem na opačných koncích věty).
- Odstraňuje potřebu sekvenčního zpracování (jako u RNN).
Multihead-attention (Vícehlavá pozornost)¶
Princip:
- Paralelní běh několika self-attention mechanismů (hlav), každá se specializuje na jiný typ vztahů.
- Hlavy pracují nezávisle, jejich výstupy se nakonec spojí.
Jak funguje:
- Rozdělení vektorů: Vstupní vektory (Q, K, V) se rozdělí na menší podprostory (např. 8 hlav → 8 podprostorů).
- Paralelní výpočet: Každá hlava provede self-attention ve svém podprostoru.
- Spojení výstupů: Výstupy hlav se spojí do jedné reprezentace lineární transformací.
Výhody:
- Model se učí různé typy závislostí najednou.
- Zvyšuje expresivitu bez exponenciálního růstu parametrů.
Masked Attention (Maskovaná pozornost)¶
Princip:
- Používá se v decoderu transformeru, aby model neviděl budoucí tokeny během generování.
- Maska: Tabulka, která zakazuje pozornosti "koukat" doprava (na tokeny, které ještě nebyly vygenerovány).
Jak funguje:
- Při výpočtu vah pozornosti se pro budoucí pozice nastaví hodnota -inf, což je v softmaxu převede na 0.
- Model se tak učí generovat výstup autoregresivně (token po tokenu, levopravě).
Použití:
- Autoregresivní úlohy: generování textu, překlad.
Cross-attention (Pozornost mezi sekvencemi)¶
Princip:
- Propojuje dvě různé sekvence (např. encoder a decoder v překladu).
- Decoder používá Query ze své aktuální pozice a Keys/Values z výstupu encoderu.
Jak funguje:
- Encoder poskytuje kontext: Výstupy encoderu slouží jako Keys a Values.
- Decoder se ptá: Queries vycházejí z aktuálního stavu decoderu.
- Vážená kombinace: Decoder kombinuje informace z encoderu na základě podobností mezi Query a Keys.
Transformer¶
Hlavní komponenty:
-
Encoder:
- Skládá se z N identických vrstev.
- Každá vrstva obsahuje:
- Multihead-self-attention
- Feed-forward síť (dvě lineární vrstvy s aktivační funkcí)
- Zbytkové spojení (residual connections) a normalizace (pro stabilní trénink).
-
Decoder:
- Také N vrstev, ale s přidanou encoder-decoder attention.
- V každé vrstvě:
- Maskovaná multihead-self-attention (vidí pouze předchozí tokeny).
- Multihead-cross-attention (propojení s výstupy encoderu).
- Feed-forward síť.
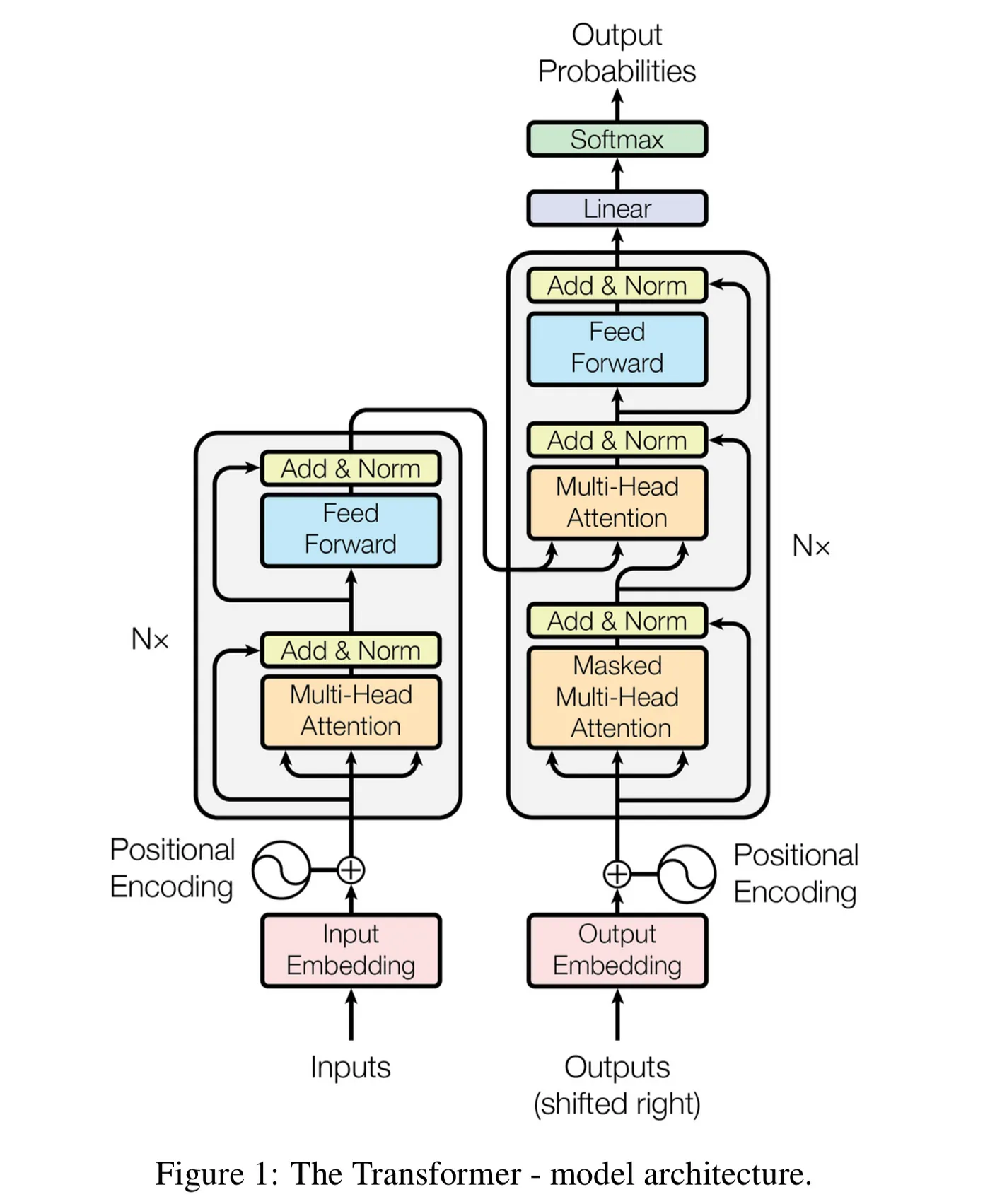
Proces zpracování:
- Vstupní embeddiny: Slova se převedou na vektory.
- Pozicové kódování: Přidá informaci o pozici slov (bez toho by Transformer nerozlišoval pořadí).
- Encoder extrahuje kontextové reprezentace.
- Decoder generuje výstup krok po kroku pomocí pozornosti na encoder a předchozí výstupy.
Nevýhody:
- Spatně udržuje dlouhý kontext. (Tisíce tokenu)
- Vyžaduje velké paměťové nároky
BERT (Bidirectional Encoder Representations from Transformers)¶
Charakteristika:
- Encoder-only architektura (pouze část encoderu z Transformeru).
- Bidirekční: Učí se kontext ze všech směrů (levo i pravo).
- Pre-trénink:
- Masked Language Model (MLM): Nahradí náhodná slova maskou a učí se je předpovídat.
- Next Sentence Prediction (NSP): Rozpozná, zda dvě věty následují za sebou.
Použití:
- Finetuning pro úlohy jako klasifikace textu, odpovídání na otázky (např. přidání klasifikační vrstvy na výstup).
Výhody:
- Zachycuje hluboký kontext celé věty.
- Univerzální reprezentace pro různé NLP úlohy.
GPT-2 (Generative Pre-trained Transformer 2)¶
Charakteristika:
- Decoder-only architektura (pouze část decoderu z Transformeru).
- Autoregresivní: Generuje text token po tokenu, vždy využívá pouze předchozí slova.
- Pre-trénink: Učí se předpovídat další slovo v sekvenci (bez učitele).
Klíčové rysy:
- Maskovaná self-attence: V každém kroku vidí pouze předchozí tokeny.
- Škálovatelnost: Velké modely (až 1.5B parametrů) s výjimečnou schopností generovat koherentní text.
Použití:
- Generování textu (články, básně, kód).
- Doplnění textu, překlad bez explicitního tréninku.
Srovnání BERT vs. GPT-2¶
| Vlastnost | BERT | GPT-2 |
|---|---|---|
| Architektura | Encoder | Decoder |
| Směr kontextu | Bidirekční (celá věta) | Unidirekční (pouze levopravý) |
| Pre-trénink | Masked LM + Next Sentence | Next token prediction |
| Typické úlohy | Klasifikace, extrakce informací | Generování textu |
| Příklad použití | Sentiment analysis, Q&A | Tvorba příběhů, automatické doplňování |
Transfer Learning: Přenos znalostí mezi úlohami¶
Základní princip:
Transfer Learning využívá znalosti získané řešením jedné úlohy (zdrojové) ke zlepšení výkonu na jiné úloze (cílové). Cílem je vyhnout se začínání od nuly a snížit potřebu velkého množství dat pro cílovou úlohu.
Klíčové komponenty:¶
- Zdrojová úloha: Úloha, na které byl model původně trénován (např. klasifikace obrázků z ImageNet).
- Cílová úloha: Nová úloha, pro kterou se model adaptuje (např. detekce nádorů na rentgenech).
- Přenos znalostí: Využití naučených vzorců (např. hran, textur) z zdrojové úlohy pro cílovou.
Metody přenosu:¶
- Fine-tuning:
- Předtrénovaný model se dále trénuje na cílových datech s upravenými vrstvami.
- Příklad: BERT předtrénovaný na obecných textech se přizpůsobí pro analýzu sentimentu recenzí.
- Feature extraction:
- Předtrénované vrstvy slouží jako pevný extraktor rysů, přidá se pouze nová klasifikační vrstva.
- Příklad: Využití konvolučních vrstev z modelu trénovaného na ImageNet pro detekci nemocí v medicínských snímcích.
Proč to funguje?¶
- Nižší vrstvy neuronových sítí se učí obecné rysy (hrany, textury), které jsou užitečné pro mnoho úloh.
- Vyšší vrstvy se specializují na konkrétní úlohu – ty se upravují při fine-tuning.
Optimalizace procesu: Hyperparametry a meta-databáze¶
Aby byl Transfer Learning efektivní, je třeba řešit dvě výzvy: výběr hyperparametrů a využití předchozích zkušeností.
Optimalizace hyperparametrů:¶
- Cíl: Najít nejlepší kombinaci parametrů (rychlost učení, počet vrstev) bez manuálního testování.
- Metody:
- Grid Search: Systematické testování všech možností – přesné, ale pomalé.
- Bayesovská optimalizace: Předpovídá slibné hyperparametry pomocí pravděpodobnostního modelu.
- Nástroje: Optuna, Hyperopt.
Meta-databáze:¶
- Účel: Ukládají výsledky předchozích experimentů (hyperparametry, architektury, výkony).
- Výhody:
- Rychlejší nalezení optimálního nastavení pro novou úlohu.
- Vyvarování se opakování neúspěšných konfigurací.
- Příklad: Google Vizier doporučuje hyperparametry na základě historických dat.
Meta Learning: Učení jak se učit¶
Meta Learning jde o krok dál než Transfer Learning. Nejde jen o přenos znalostí, ale o naučení algoritmu, jak se efektivně učit nové úlohy.
Základní koncepty:¶
- Epizodické učení: Model se trénuje na mnoha podobných úlohách (např. rozpoznávání 50 druhů zvířat), aby se naučil obecné strategie.
- Optimalizace inicializace: Hledá se počáteční nastavení modelu, ze kterého se rychle adaptuje na novou úlohu (např. MAML).
Model-Agnostic Meta-Learning (MAML):¶
- Princip: Model se naučí univerzální počáteční váhy, které lze rychle upravit pro jakoukoli novou úlohu.
- Kroky:
- Meta-trénink: Pro každou úlohu se provedou 1–3 kroky gradient descentu a upraví se počáteční váhy.
- Meta-testování: Na nové úloze se model adaptuje za pár kroků (např. 5 příkladů pro few-shot learning).
- Příklad: Robot se naučí manipulovat s různými předměty v simulaci a rychle se adaptuje v reálném světě.
Automatizace návrhu modelů: NAS a AutoML¶
Aby se snížila závislost na lidských expertech, vznikly metody pro automatický návrh architektur a kompletní automatizaci ML pipeline.
Neural Architecture Search (NAS):¶
- Cíl: Automaticky najít optimální architekturu sítě pro danou úlohu.
- Metody:
- Reinforcement Learning (RL): Agent zkouší různé architektury a dostává odměnu za dobrý výkon.
- Evoluční algoritmy: Mutace a křížení existujících architektur.
- Gradient-based metody: Hledání architektury pomocí gradientů (např. DARTS).
- Příklad: NAS navrhl EfficientNet, který překonává ručně navržené modely v efektivitě.
AutoML (Automatizované strojové učení):¶
- Rozsah: Automatizuje celý proces ML – od předzpracování dat po výběr modelu a hyperparametrů.
- Nástroje:
- AutoKeras: Open-source knihovna pro automatický výběr architektur.
- Google AutoML: Umožňuje trénovat modely bez kódování.
- Příklad: Uživatel nahraje data o prodejích a AutoML vygeneruje prediktivní model.
Few-shot Learning: Učení z minimálních dat¶
Few-shot Learning je přirozeným důsledkem Meta a Transfer Learningu. Cílem je naučit se novou úlohu z 1–5 příkladů na třídu.
Metody:¶
- Meta-learningové přístupy (MAML): Model se naučí rychle adaptovat z obecných znalostí.
- Metric Learning: Učí se měřit podobnost mezi příklady (např. pomocí Siamese sítí).
- Příklad: Po zobrazení 3 obrázků "klokana" model správně klasifikuje nový obrázek.
Proč je to možné?¶
- Meta Learning poskytuje obecné strategie učení.
- Transfer Learning využívá předtrénované rysy (např. z ImageNet).
Propojení konceptů¶
- Transfer Learning řeší konkrétní přenos znalostí mezi úlohami.
- Meta Learning generalizuje tento proces – učí se, jak se učit.
- NAS a AutoML automatizují návrh modelů, což zrychluje aplikaci Transfer/Meta Learningu.
- Few-shot Learning je praktickým výsledkem – model se učí nové úlohy s minimem dat.