4. Metody pro hodnocení a výběr příznaků (univarietní/multivarietní metody, filtrační/wrapper/embedded metody). Selektivní/adaptivní metody redukce počtu instancí: Condensed Nearest Neighbor (CNN), Delauney/Gabriel/RNG grafy, Wilsonova editace, Multi-edit metoda, Tomkovy spoje. (NI-PDD)¶
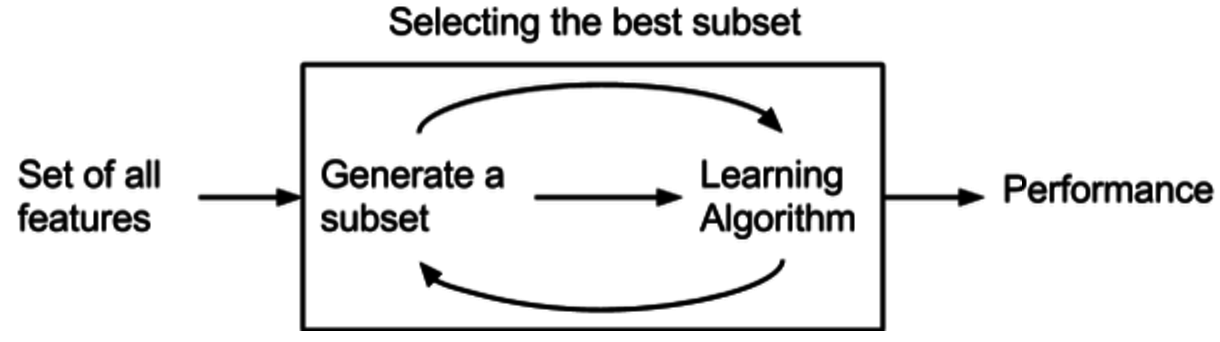
Hodnocení a výběr příznaků¶
Taxonomie¶
- Univarietní Metody: Metody které berou v úvahu pouze jeden příznak
- Multivarietní Metody: Metody které berou v úvahu podmnožinu příznaků
- Filtrační Metody:
- Hodnotí příznaky nezávisle na učícím algoritmu
- Používají statistické míry (korelace, informační zisk, chi-kvadrát test)
- Čím vetší je rozděleni mezi dvěma sadami dat tím vice relevantní je příznak
- Pokud P(X_i | Y=1) = P(X_i|Y=0) tak jsou nerelevantní
- Rychlé a výpočetně nenáročné
- Neberou v úvahu interakce mezi příznaky
- Vhodné pro počáteční redukci velkého množství příznaků

- Wrapper Metody:
- Používají učící algoritmus jako černou skříňku pro hodnocení podmnožin příznaků
- Hledají optimální podmnožinu příznaků pro daný algoritmus
- Výpočetně náročnější než filtrační metody
- Berou v úvahu interakce mezi příznaky
- Příklady: dopředná selekce, zpětná eliminace, rekurzivní eliminace příznaků
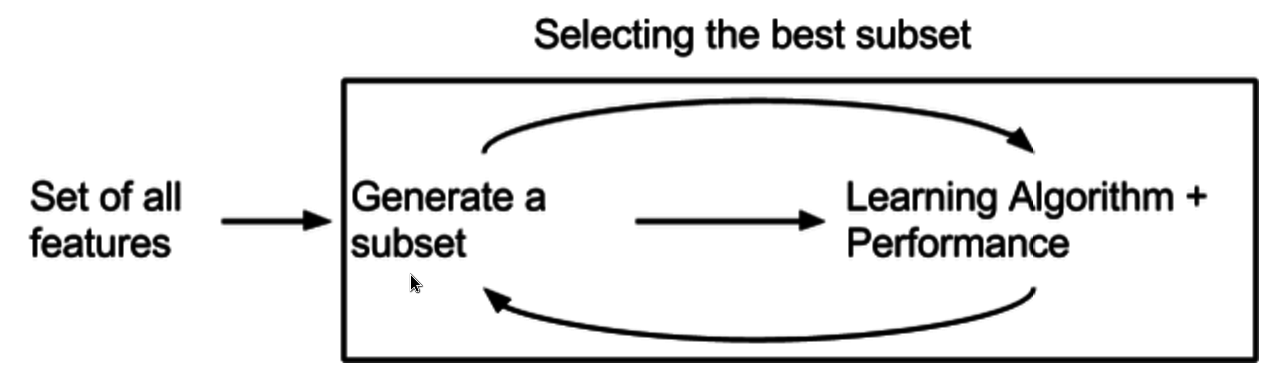
- Embedded Metody:
- Výběr příznaků je součástí trénovacího procesu
- Kombinují výhody filtračních a wrapper metod
- Efektivnější než wrapper metody
- Uni/Multi varietní: Specifické pro daný učící algoritmus
- Příklady: LASSO regularizace, rozhodovací stromy s výběrem příznaků
Metody¶
T-Testy¶
- Jedná se o univarietní a filtrační metodu
- Testuje statistickou významnost rozdílu středních hodnot příznaku mezi třídami
- Vhodné pro binární klasifikaci a normálně rozdělená data
- Výstupem je p-hodnota určující významnost příznaku
Korelace¶
- Univarietní a filtrační metoda
- Měří lineární závislost mezi příznaky nebo příznakem a cílovou proměnnou
- Pearsonova korelace pro spojité proměnné
- Spearmanova korelace pro ordinální data
- Vysoká korelace mezi příznaky indikuje redundanci
Entropie¶
- Univarietní a filtrační metoda
- Měří míru neurčitosti/informace v příznaku
- Používá se pro výpočet:
- Informačního zisku (Information Gain)
- Vzájemné informace (Mutual Information)
- Gain Ratio
- Vhodné pro kategorické příznaky
- Nepreferuje příznaky s velkým počtem hodnot (na rozdíl od Information Gain)
Selektivní/adaptivní metody redukce počtu instancí¶
Metody pro redukci počtu instancí (instance selection/reduction) zmenšuji velikost trénovací množiny při zachování její reprezentativnosti a klasifikační schopnosti.
Hlavní cíle:
- Redukce paměťové a výpočetní náročnosti
- Odstranění šumu a outlierů
- Zlepšení generalizace modelu
- Zrychlení klasifikace (zejména pro metody založené na instancích jako k-NN)
Základní přístupy:
-
Selektivní metody:
- Vybírají podmnožinu původních instancí
- Zachovávají původní instance beze změny
-
Adaptivní metody:
- Mohou vytvářet nové instance
- Upravují nebo kombinují existující instance
Condensing Metody¶
- přístup ke snižování počtu prvků
- zanechává pouze prvky, které jsou nezbytné k vytvoření decision boundary (hranice rozdělení)
Condensed Nearest Neighbor Rule (CNN rule)¶
Condensing¶
- Decision Boundary Consistent
- Z dat vezme podmnožinu, jejíchž shluky budou vytvářet stejné hranice rozdělení bodů v prostoru
- Minimum Consistent Set
- Nejmenší možná podmnožina, které umožňuje správně klasifikovat všechna původní data
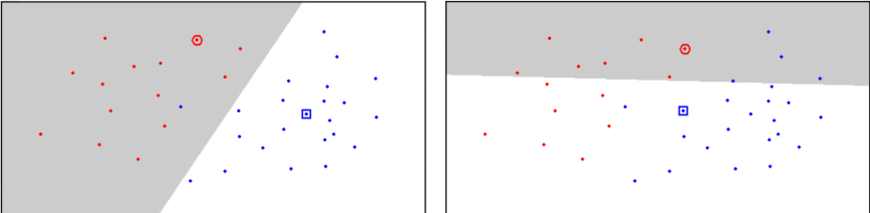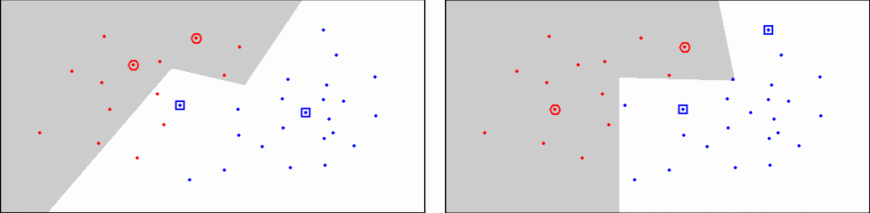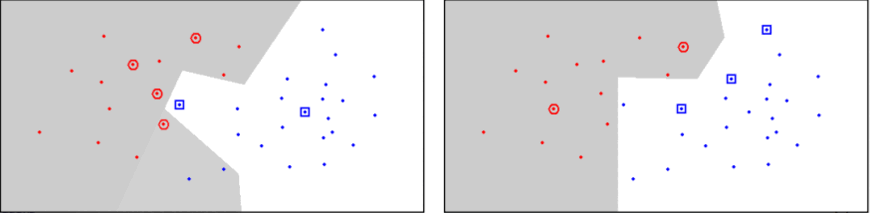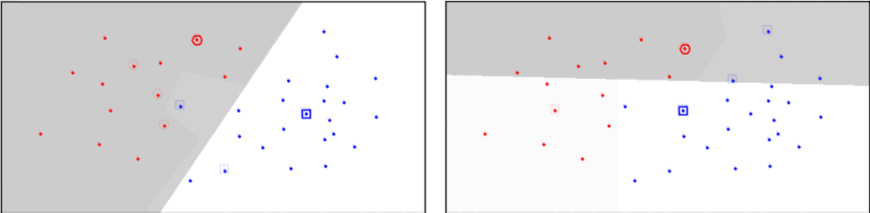
CNN¶
- Slouží k výběru bodů, které jsou na pomezí tříd
- Iterativní metoda, která 100 % odděluje data jednotlivých tříd
- Citlivý na šum, takové prvky jsou často klasifikovány špatně
- Vytváří různé hranice v závislosti na pořadí
Algoritmus
-
Inicializace:
- Vezmeme prázdnou množinu STORE
- Přidáme do ní první bod z trénovací množiny
-
Hlavní proces:
- Procházíme všechny body z trénovací množiny
- Každý bod se pokusíme klasifikovat pomocí bodů ve STORE
- Pokud je klasifikace špatná, přidáme tento bod do STORE
- Opakujeme, dokud v jednom průchodu nepřidáme žádný nový bod
Proximity Graphs Metody¶
- Ponechá v datasetu pouze body ze shluků, ve kterých jsou sousední body patřící do jiných tříd (ponechává body na hranici)
Delaunay Triangulation¶
- 3 body jsou považovány za sousedy, pokud kružnice, která má tyto 3 body na sobě, neobsahuje žádné jiné body
- Voronoi editing využívá tohoto principu
- Nechá v datasetu pouze body ze shluků, ve kterých jsou sousední body patřící do jiných tříd
- Ponechává body na hranici
Gabriel¶
- Podmnožina Delaunay Triangulation
- Kružnice tvořeny pouze 2 body,
- neumožňuje bod uvnitř kruhu
- Méně náročné na výpočet oproti Delaunayovi
RNG¶
- Používá “lune” namísto kružnice
- Lune: oblast průniku dvou kružnic se středy v těchto bodech a poloměrem rovným vzdálenosti mezi bod
- Lune neobsahuje zadny jiny bod
- Není zaručeno, že je training set consistent
Delaunay x Gabriel x RNG¶
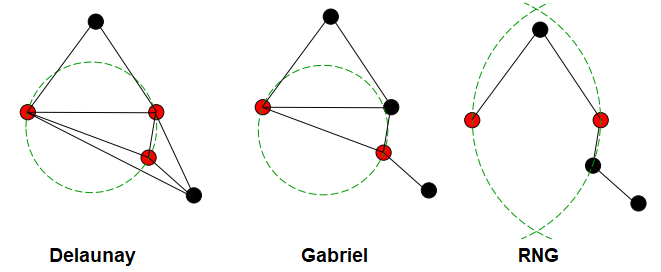
Editing Metody¶
- Snaha odebrat body šumu z dat a tím zlepšit klasifikaci
- Kombinace Editingu a Condensingu
Wilson Editing¶
- Odebrání bodů jež se neshodují s majoritou z jejich K nejbližších sousedů
Multi-edit¶
- Opakovaná aplikace Wilson Editing na random subsety
- Klasifikuje vzor podle 1-NearestNeighbour pravidla. Tedy nejbližší soused musí mít stejný vzor
Tomkovy spoje¶
- Pomáhá odstranit šum a hraniční prvky
- Najdeme Tomkovy spoje, a odebereme všechny majoritní prvky, které jsou součástí Tomkových spojů
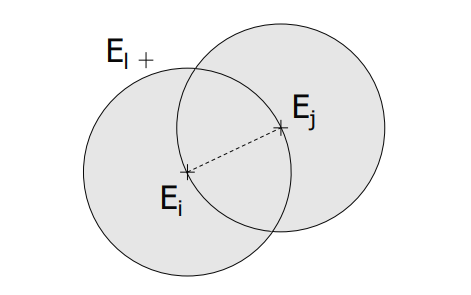
- Pár instancí (E_i,E_j) tvoří Tomkův spoj, pokud:
- E_j je nejbližší soused E_i
- E_i je nejbližší soused E_j
- E_i a E_j patří do různých tříd
- Metoda sama o sobě není moc účinná, ale v kombinaci s jinými se používá často