5. Algoritmy pro nahrazování chybějících hodnot. Detekce a ošetření odlehlých hodnot. Vyvažování skupin dat (undersampling/oversampling metody). (NI-PDD)¶
Algoritmy pro nahrazování chybějících hodnot¶
Chybějící, nebo prázdné hodnoty¶
- Ve zdrojových datech často nelze odlišit chybějící a schválně nevyplněnou hodnotu
- Mohou vznikat různými způsoby:
- Technické problémy při sběru dat
- Nevyplněné hodnoty v dotaznících
- Chyby při přenosu nebo ukládání dat
Algoritmy¶
-
Nedělat nic
- Použít relevantní reprezentaci pro chybějící hodnotu
- Například NaN = -1, pokud všechny ostatní hodnoty jsou kladné
-
Vymazání
- Listwise: smaže celý řádek, kde chybí alespoň jedno pole
- Pairwise: jako listwise, ale zaměřeno na důležité příznaky
- Smazání příznaku: pokud chybí pro většinu datových bodů
-
Imputace
- Doplnění hodnot pomocí:
- Průměr či medián sloupce
- Průměr k-NN (vhodné pouze pro nízkodimenzionální data)
- Interpolace mezi existujícími hodnotami
- Doplnění hodnot pomocí:
k-NN (k-Nearest Neighbors)¶
Princip:
- Pro záznam s chybějící hodnotou najde k nejbližších sousedů
- Chybějící hodnotu nahradí na základě hodnot těchto sousedů
Algoritmus:
- Pro záznam s chybějící hodnotou:
- Vypočítá vzdálenost ke všem ostatním záznamům (používá pouze existující hodnoty)
- Vybere k nejbližších sousedů
- Nahradí chybějící hodnotu:
- Pro numerické hodnoty: průměrem nebo mediánem hodnot sousedů
- Pro kategorické hodnoty: nejčastější hodnotou mezi sousedy
Detekce a ošetření odlehlých hodnot¶
Základní charakteristika¶
- Odlehlé hodnoty (outliers): anomálie odchylující se od ostatních pozorování
- Po identifikaci je nutná analýza původu odchylky:
- Lidská chyba
- Chyba měření
- Experimentální chyba
- Samplingová chyba
Detekce odlehlých hodnot
-
Univarietní pohled:
- Ručně stanoveni maximálních minimálních hranice
- Zjišťovaní pomoci statistických metod: průměr median...
-
Multivarietní pohled:
- Shlukování založené na vzdálenosti
- Density-based přístupy
- Modelové přístupy
Algoritmy detekce
-
LOF (Local Outlier Factor)
- Měří lokální odchylku bodu vzhledem k jeho sousedům
- \text{LOF}(a) = \frac{\text{průměrná lokální hustota sousedů}}{\text{lokální hustota }a}
- \text{LOF}(a) ≈ 1: bod a je podobný svým sousedům (podobná hustota)
- \text{LOF}(a) > 1: bod a je v řidší oblasti než jeho sousedé - indikuje anomálii
-
K-means
- Iterativní tvorba k center
- Přiřazování prvků nejbližším centrům
- Přepočet center jako průměrů
- Outliers jsou body daleko od všech center
-
Density-based
- Identifikace bodů v řídkých oblastech
- Využití hustoty bodů v okolí
- Například DBSCAN algoritmus
Ošetření odlehlých hodnot
-
Odstranění
- Kompletní odstranění záznamu
- Vhodné při jasné chybě
-
Nahrazení
- Průměrem nebo mediánem
- kNN imputace
- Interpolace
-
Transformace dat
- Logaritmická transformace
- Normalizace
- Standardizace
-
Vytvoření speciální kategorie
- Označení jako "jiné"
- Binning do kategorií
Vyvažování skupin dat¶
Undersampling¶
Tomkovy spoje¶
- Pomáhá odstranit šum a hraniční prvky
- Najdeme Tomkovy spoje, a odebereme všechny majoritní prvky, které jsou součástí Tomkových spojů
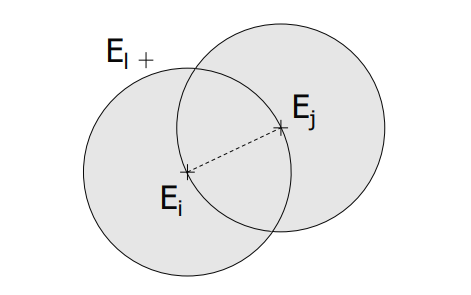
- Pár instancí (E_i,E_j) tvoří Tomkův spoj, pokud:
- E_j je nejbližší soused E_i
- E_i je nejbližší soused E_j
- E_i a E_j patří do různých tříd
- Metoda sama o sobě není moc účinná, ale v kombinaci s jinými se používá často
Extended Nearest Neighbor (ENN)¶
- Agresivnější metoda odebírání než Tomek links
- Odebere každý bod, jehož třída se liší od třídy aspoň dvou ze tří jeho nejbližších sousedů
- Čistí data důkladněji, ale může odstranit i užitečné instance
Neighbourhood Cleaning Rule (NCL)¶
- Zaměřuje se především na čištění dat než na redukci
- Kombinuje ENN s dodatečnými pravidly pro majoritní třídu
- Algoritmus:
- Odebere majoritní instance, pokud 3 nejbližší sousedé jsou minoritní
- Odebere 3 majoritní instance, pokud jsou nejbližšími sousedy minoritní instance
Oversampling¶
SMOTE (Synthetic Minority Oversampling Technique)¶
Princip: - Technika pro vyvažování nevyvážených datasetů - Vytváří nové syntetické vzorky pro minoritní třídu - Generuje data interpolací mezi existujícími vzorky minoritní třídy
Algoritmus: 1. Pro každý vzorek minoritní třídy: - Najde k nejbližších sousedů ze stejné třídy - Vybere náhodně jednoho z těchto k sousedů - Vytvoří nový syntetický vzorek: - Vypočítá rozdíl mezi vybraným vzorkem a jeho sousedem - Vynásobí tento rozdíl náhodným číslem mezi 0 a 1 - Přičte k původnímu vzorku
Vlastnosti: - Nevytváří pouhé kopie existujících vzorků - Generuje nové vzorky podél linie spojující sousední body - Typicky se používá k = 5 nejbližších sousedů - Vytváří obecnější vzorky než prostá replikace
Nevýhody: - Nebere v úvahu majoritní třídu při vytváření nových vzorků - Může způsobit problémy při silném překryvu tříd - Výpočetně náročné pro velké datasety
Kombinované přístupy¶
SMOTE + Tomek links¶
- SMOTE může vytvořit umělou minoritu někde v majoritní části
- Následné odebrání obou vzorků tvořících Tomkův spoj
- Pomáhá vyčistit překrývající se oblasti
SMOTE + ENN¶
- Podobný princip jako SMOTE + Tomek
- Pročistí více instancí než Tomek links
- Agresivnější čištění hraničních oblastí
- Vhodné při velkém překryvu tříd