7. Učení dopředných neuronových sítí, konvoluční neuronové sítě a jejich regularizace. (NI-MVI)¶
Učení dopředných neuronových sítí¶
- Účel: Trénink dopředných neuronových sítí (feedforward neural networks) pro řešení úloh, jako je klasifikace, regresní analýza nebo predikce. Cílem je minimalizovat chybu mezi předpovědí sítě a skutečnými hodnotami.
- Vlastnosti:
- Informace proudí jednosměrně od vstupní vrstvy přes skryté vrstvy až k výstupní vrstvě.
- Žádné zpětné vazby mezi neurony (na rozdíl od rekurentních sítí).
- Aktivace neuronů se počítají pomocí vážené sumy vstupů a aktivační funkce (např. ReLU, sigmoid, tanh).
- Proces učení:
- Inicializace váh: Váhy a biasy jsou náhodně inicializovány.
- Dopředná propagace: Výpočet výstupu sítě na základě aktuálních váh.
- Výpočet chyby: Porovnání výstupu sítě s cílovými hodnotami pomocí ztrátové funkce (např. MSE, cross-entropy).
- Zpětná propagace (backpropagation): Spočítání gradientů chybové funkce podle váh pomocí řetězového pravidla.
- Aktualizace váh: Gradientní sestup nebo jeho varianty (např. SGD, Adam) pro optimalizaci váh.
- Iterace: Proces se opakuje po dobu tréninku nebo dokud se chyba dostatečně nesníží.
- Použití:
- Klasifikace obrazů, textu a zvuku.
- Predikční modely v různých oblastech (např. finance, medicína).
Perceptron (Optional)¶
Základní charakteristika:
- Nejjednodušší forma neuronové sítě pro binární klasifikaci
- Modelován podle biologického neuronu
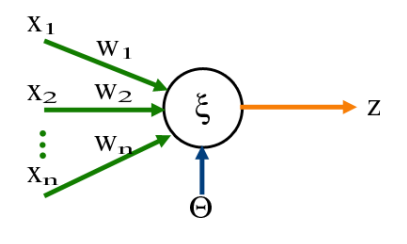
Komponenty:
-
Vstupní vrstva:
- Přijímá numerické hodnoty
- Každý vstup má přiřazenou váhu
-
Váhy a bias:
- Váhy určují sílu spojení mezi neurony
- Bias posouvá rozhodovací hranici
-
Výpočetní proces:
- Vážený součet vstupů: \sum(w_i * x_i) + b
- Kde w_i jsou váhy, x_i vstupy a b je bias
-
Aktivační funkce:
- Určuje výstup perceptronu (0 nebo 1)
- Běžné typy: skoková funkce, sigmoid, ReLU
Učení perceptronu:
- Iterativní proces úpravy vah
- Váhy se upravují podle chyby: w_{new} = w + \eta(y - \hat{y})x
- Kde \eta je learning rate, y je skutečná hodnota a \hat{y} je predikovaná hodnota
Backpropagation (Optional)¶
Základní princip:
- Algoritmus pro učení neuronových sítí pomocí zpětného šíření chyby
- Cílem je minimalizovat rozdíl mezi předpovězeným a skutečným výstupem úpravou vah a biasů v síti
Proces učení obsahuje čtyři hlavní kroky:
-
Dopředný průchod (Forward pass):
- Data jsou přivedena na vstupní vrstvu
- Každý vstup je vynásoben odpovídající váhou
- Výsledky postupují přes neurony skrytých vrstev
- Na každém neuronu je aplikována aktivační funkce
- Proces pokračuje až k výstupní vrstvě
-
Výpočet chyby:
- Porovnání výstupu sítě se skutečnou hodnotou
- Výpočet chybové funkce (např. střední kvadratická chyba)
-
Zpětný průchod (Backward pass):
- Chyba se propaguje zpět sítí od výstupní vrstvy
- Pomocí řetězového pravidla (derivace) se počítají gradienty chybové funkce
- Chain rule : \frac{\delta f(g(x))}{\delta x} = \frac{\delta f}{\delta g} \frac{\delta g}{\delta x}
- Určuje se příspěvek každé váhy k celkové chybě
-
Aktualizace vah:
- Váhy jsou upraveny na základě vypočtených gradientů
- Velikost úprav je řízena learning rate (učící konstantou)
- Proces se opakuje, dokud se chyba nesníží na přijatelnou úroveň
Konvoluční neuronové sítě (CNN)¶
- Účel: Modelování dat s prostorovou strukturou (např. obrazů) pomocí konvolučních operací, které extrahují lokální vzory a hierarchické rysy.
- Vlastnosti:
- Využívají konvoluční vrstvy místo plně propojených vrstev pro efektivní zpracování dat.
- Každý neuron ve vrstvě je spojen pouze s malou částí vstupu (receptivní pole).
- Obsahují tři hlavní typy vrstev:
- Konvoluční vrstva: Aplikuje filtry (kernely) na vstupní data a extrahuje rysy.
- Pooling vrstva: Redukuje rozměry dat (např. max-pooling nebo average-pooling), čímž zvyšuje robustnost vůči posunům a šumu.
- Plně propojená vrstva: Na konci sítě kombinuje extrahované rysy pro klasifikaci nebo regresi.
- Proces učení:
- Stejný jako u dopředných sítí (dopředná propagace, výpočet chyby, zpětná propagace a aktualizace váh).
- Specifická zpětná propagace pro konvoluční vrstvy zahrnuje gradienty filtrů a pooling operací.
- Použití:
- Klasifikace obrazů (např. rozpoznávání obličejů, objektů).
- Segmentace obrazů a detekce objektů.
- Zpracování sekvenčních dat (např. zvukové signály).
Regularizace neuronových sítí¶
- Účel: Zabránit přeučení modelu na trénovacích datech a zvýšit jeho schopnost generalizace na neznámá data.
- Metody regularizace:
- L1 a L2 regularizace:
- Přidání penalizačního členu do ztrátové funkce.
- L1 regularizace (Lasso) tlačí některé váhy přesně na nulu a tím efektivně vybírá důležité příznaky
- L2 regularizace (Ridge) pouze zmenšuje všechny váhy rovnoměrně, ale ponechává je nenulové
- Dropout:
- Náhodné "vypnutí" některých neuronů během tréninku, aby síť nezávisela příliš na konkrétních neuronech.
- Zvyšuje robustnost modelu tím, že simuluje ensemble efekt více sítí.
- Datová augmentace:
- Umělé zvětšení trénovací množiny pomocí transformací dat (např. rotace, oříznutí, šum).
- Zlepšuje generalizaci modelu na různorodější data.
- Early stopping:
- Ukončení tréninku v okamžiku, kdy se chyba na validační sadě začne zhoršovat, aby se zabránilo přeučení.
- Batch Normalization:
- Normalizuje aktivace v každé vrstvě během tréninku, což stabilizuje učení a umožňuje použití vyšších učících rychlostí.
- L1 a L2 regularizace: