8. Autoencodery a generativní neuronové sítě. (NI-MVI)¶
Autoencodery¶
Charakteristika:
- Speciální typ neuronové sítě, který se učí zrekonstruovat svůj vlastní vstup
- Pracuje se dvěma hlavními částmi: enkodér komprimuje vstupní data do latentního prostoru a dekodér se snaží tato data rekonstruovat zpět
- Učí se v režimu bez učitele, jelikož k tréninku mu stačí nestrukturovaná data
- Slouží k zachycení základních vzorů a rysů v datech
Praktické využití:
- Dimenzionalita: Nelineární redukce dimenzionality s menšími ztrátami než klasické metody (např. PCA)
- Anomálie: Detekce neobvyklých vzorů, které autoencoder nedokáže dobře rekonstruovat
- Denoising: Odstranění šumu z obrazu nebo jiných signálů
- Kompresní techniky: Efektivní kódování a dekódování informací bez ztráty klíčových rysů
Princip fungování¶
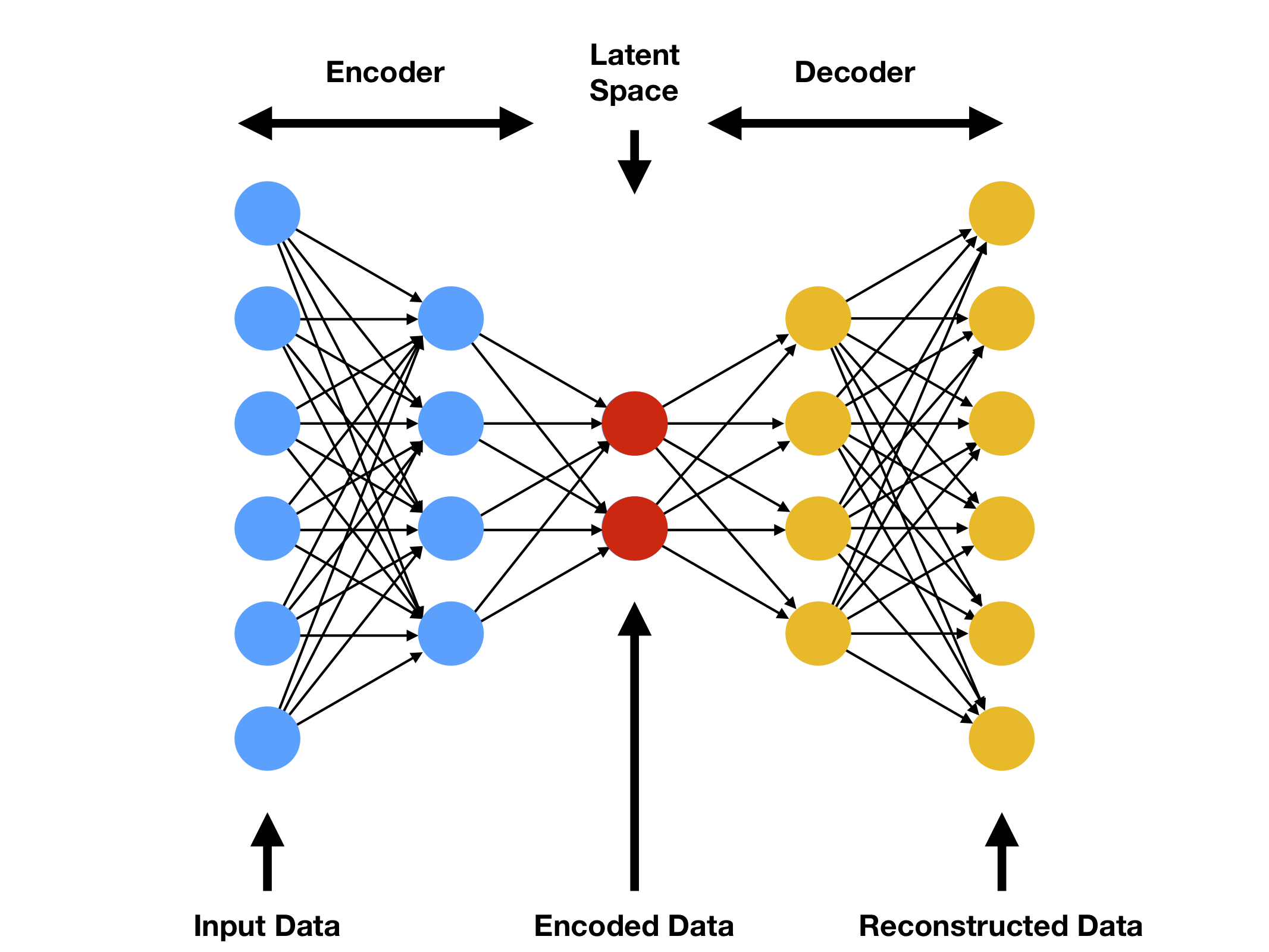
- Enkodér:
- Přijímá vstupní data x a transformuje je do latentního prostoru z
- Typicky obsahuje několik vrstev, které postupně snižují dimenzionalitu
- Latentní prostor:
- Komprimovaná reprezentace dat s nižší dimenzí
- Zachycuje nejdůležitější rysy a vzory ze vstupních dat
- Může být regulován (např. sparse coding, variační přístup)
- Dekodér:
- Přijímá latentní reprezentaci z a rekonstruuje původní data x'
- Zrcadlová struktura k enkodéru
- Cílem je minimalizovat rekonstrukční chybu
- Minimalizovat rozdíl mezi původním vstupem a výstupem dekodéru
Typy Autoencoderů¶
- Undercomplete Autoencoder
- Latentní prostor má menší rozměr než původní data.
- Omezení velikosti skryté vrstvy samo o sobě funguje jako _regularizace
- Sparse Autoencoder
- Může mít více neuronů ve skrytých vrstvách než vstup, ale aktivních je vždy jen malé množství
- Zahrnuje sparsity term v chybě, aby penalizoval příliš mnoho aktivovaných neuronů.
- Denoising Autoencoder
- Do vstupu se přidává šum, síť se učí rekonstruovat původní “čistá” data
- Pomáhá síti naučit se robustnější reprezentace a odstraňovat šum v reálných datech.
- Contractive Autoencoder
- Penalizuje citlivost latentního prostoru vůči malým změnám ve vstupu.
- Minimalizuje se derivace výstupu vzhledem k vstupu, čímž se posiluje robustnost rozpoznaných rysů
- Variational Autoencoder (VAE)
- Generativní typ autoencoderu, který na rozdíl od ostatních typů pracuje s pravděpodobnostním rozdělením v latentním prostoru
- Encoder vytváří pro každý vstup dvě hodnoty: průměr (μ) a směrodatnou odchylku (σ)
- Místo přímého zakódování do bodu v latentním prostoru kóduje data do normálního rozdělení:
- Pro každý vstup definuje "oblast" v latentním prostoru pomocí μ a σ
- Z této oblasti náhodně vzorkuje body pomocí tzv. reparametrizačního triku: z = μ + σ * ε, kde ε je náhodný šum
- Loss funkce se skládá ze dvou částí:
- Reconstruction Loss: jak dobře dokáže dekodér rekonstruovat původní vstup
- KL Divergence: nutí rozdělení v latentním prostoru být blízko standardnímu normálnímu rozdělení N(0,1)
- Výhody tohoto přístupu:
- Můžeme generovat nová data vzorkováním z latentního prostoru
- Latentní prostor je spojitý a smysluplně organizovaný (podobné vstupy mají podobné kódování)
- Směrodatná odchylka umožňuje modelu vyjádřit nejistotu o vstupních datech
Generativní neuronové sítě (GAN)¶
- Základní princip
- GAN (Generative adversarial network) využívá dva modely:
- Generátor vytváří falešná data (např. umělé obrázky),
- Diskriminátor se je snaží rozlišit od reálných příkladů
- Trénování je adverzární (dva modely si „konkurují“):
- Generátor se učí produkovat co nejrealističtější výstup,
- Diskriminátor se učí rozlišit falešný výstup od skutečných dat.
- GAN (Generative adversarial network) využívá dva modely:
- Praktické využití
- Generování realistických obrazů (tváře, objekty, stylizované obrázky).
- Data augmentation – rozšíření trénovacích sad v počítačovém vidění.
- Super-resolution – zvětšování rozlišení obrázků.
Princip fungování¶
- Struktura
- Generátor
- Vstupuje mu náhodný šum (vektor) z prostoru zvaného latentní prostor.
- Často Gaussovský šum
- Jeho cílem je transformovat tento šum na data, která vypadají “reálně”
- Vstupuje mu náhodný šum (vektor) z prostoru zvaného latentní prostor.
- Diskriminátor
- Klasifikátor, který dostává reálná data i výstup generátoru.
- Vrací pravděpodobnost, že vstup je reálný (tj. z trénovací množiny) nebo falešný (ze generátoru).
- Generátor
- Trénování
- Fáze diskriminátoru:
- Diskriminátor se trénuje na rozlišování mezi reálnými vzorky a vzorky z generátoru.
- Minimalizuje chybu při klasifikaci reálných a falešných dat.
- Fáze generátoru:
- Váhy diskriminátoru se dočasně zmrazí.
- Generátor se snaží „obalamutit“ diskriminátor, aby falešný výstup označil jako reálný
- Generátor minimalizuje svou vlastní chybu, kterou udává zpětná vazba od diskriminátoru.
- Fáze diskriminátoru:
- Vyváženost hry
- Pokud je diskriminátor moc silný, generátor se nenaučí dostatečně kvalitní výstupy.
- Pokud je naopak generátor příliš úspěšný, diskriminátor přestane rozlišovat.
- Výsledkem trénování by měla být rovnováha, kdy generátor produkuje data, která diskriminátor téměř nemůže spolehlivě odlišit.