9. Rekurentní neuronové sítě a jejich učení, neuroevoluce. (NI-MVI)¶
Rekurentní neuronové sítě (RNN)¶
Základní principy
- Navrženy pro zpracování sekvenčních dat (text, časové řady, řeč).
- Obsahují skrytý stav, který přenáší informace mezi kroky sekvence.
- Umožňují modelování závislostí mezi prvky v sekvenci.
Super video nebo medium clanek
Princip uceni¶
Backpropagation Through Time (BPTT)¶
- Algoritmus pro trénování rekurentních sítí, který rozvine síť v čase a aplikuje backpropagaci na každý krok sekvence.
- Umožňuje počítat gradienty chyby nejen prostorově (mezi vrstvami), ale i časově (mezi kroky sekvence).
Algoritmus¶
-
Rozvinutí sítě v čase:
- Síť se "nakopíruje" pro každý časový krok sekvence (např. pro větu o 10 slovech vznikne 10 kopií sítě).
- Každá kopie odpovídá jednomu kroku a sdílí stejné váhy.
-
Dopředný průchod:
- Pro každý krok se vypočítá výstup sítě (hidden state a cell state pro LSTM).
- Ukládají se mezivýstupy (brány, stavy) pro pozdější výpočet gradientů.
-
Výpočet celkové chyby:
- Chyba se spočítá pro každý krok (např. rozdíl mezi predikcí a skutečnou hodnotou).
- Celková chyba = součet chyb přes všechny kroky.
-
Zpětný průchod časem:
- Gradienty chyby se počítají od posledního kroku k prvnímu.
- Pro každý krok:
- Vypočítají se gradienty pro váhy bran (forget, input, output u LSTM; update, reset u GRU).
- Aktualizují se gradienty pro cell state (LSTM) nebo skrytý stav (GRU).
- Gradienty z jednotlivých kroků se sečtou (protože váhy jsou sdílené).
-
Aktualizace vah:
- Gradienty se použijí pro aktualizaci vah pomocí optimalizačního algoritmu (např.
Architektury¶
Elmanova síť (Elman Network)¶
Architektura:
- Vstupní vrstva → Skrytá vrstva (tanh/ReLU) → Kontextová vrstva (zpožděná kopie skryté vrstvy) → Výstupní vrstva.
- Příklad: Při zpracování textu předpovídá další slovo na základě předchozích slov.
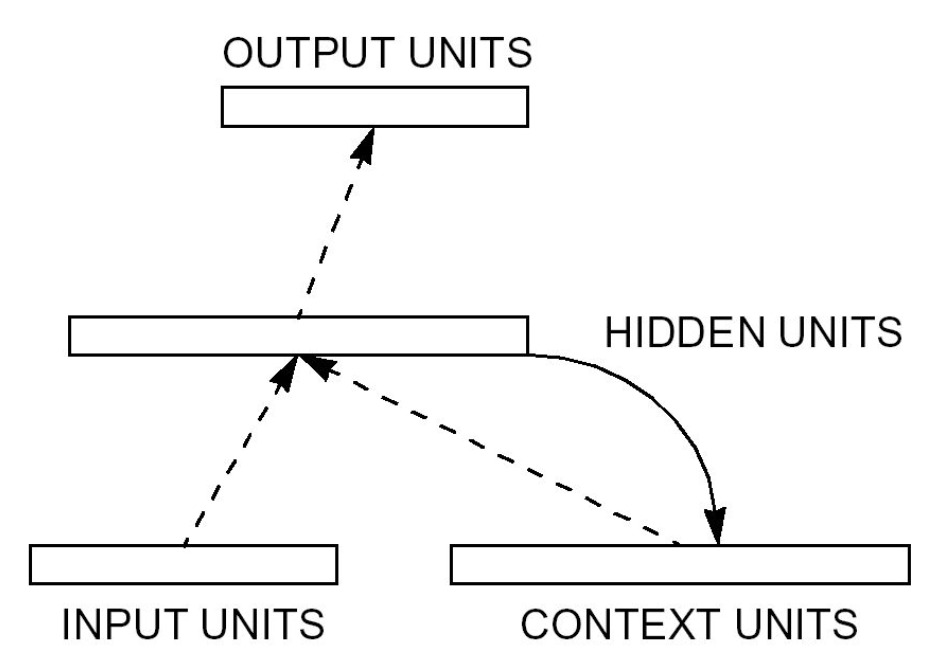
Princip fungování:
- Krátkodobá paměť: Uchovává informace z předchozího kroku v kontextové vrstvě, která kopíruje výstupy skryté vrstvy.
- Zpracování sekvencí: V každém časovém kroku zpracovává nový vstup a kombinuje ho s informací z minulosti (z kontextové vrstvy).
- Jednoduchá rekurence: Rekurentní spojení je pevné (bez učení), pouze přenáší stav skryté vrstvy do dalšího kroku.
Aplikace:
- Predikce časových řad (teplota, akcie).
- Jednoduché generování textu.
Problémy:
- Krátká paměť (neumí pracovat s dlouhými závislostmi).
- Trpí mizejícími gradienty (učení selhává u dlouhých sekvencí).
Hopfieldova síť (Hopfield Network)¶
Architektura:
- Plně propojené neurony (každý neuron spojen s každým).
- Symetrické váhy: Váha mezi neuronem A a B je stejná jako mezi B a A.
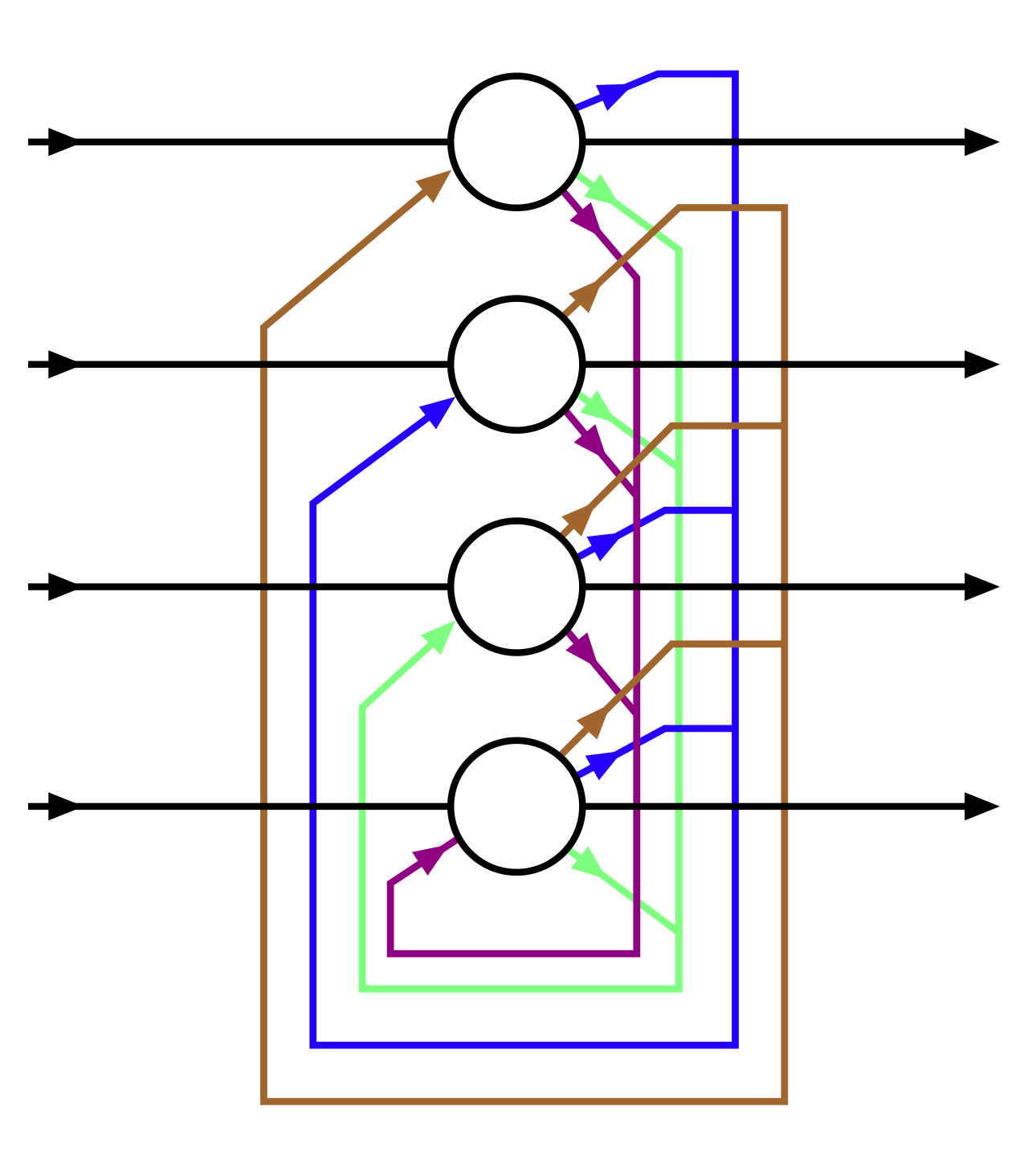
Princip fungování:
- Asociativní paměť: Ukládá vzory (např. obrázky) a dokáže je rekonstruovat i z poškozených vstupů.
- Energetické minimum: Síť "relaxuje" do stabilního stavu (uloženého vzoru) přes aktualizaci neuronů.
Jak pracuje:
- Uložení vzorů: Váhy se nastaví podle Hebbova pravidla ("neurony, které se aktivují společně, spojují se").
- Rekonstrukce: Poškozený vstup se iterativně aktualizuje, dokud síť nedosáhne stabilního stavu (uloženého vzoru).
Aplikace:
- Obnova poškozených dat (obrazce, text).
- Řešení optimalizačních problémů (např. problém obchodního cestujícího).
Limity:
- Malá kapacita (maximálně ~14 % počtu neuronů).
- Riziko falešných stabilních stavů.
LSTM (Long Short-Term Memory)¶
Architektura:
- Paměťový článek (cell state) → prochází sítí a upravuje se pomocí bran.
- Skrytý stav (hidden state) → výstup pro aktuální krok a vstup pro další krok.
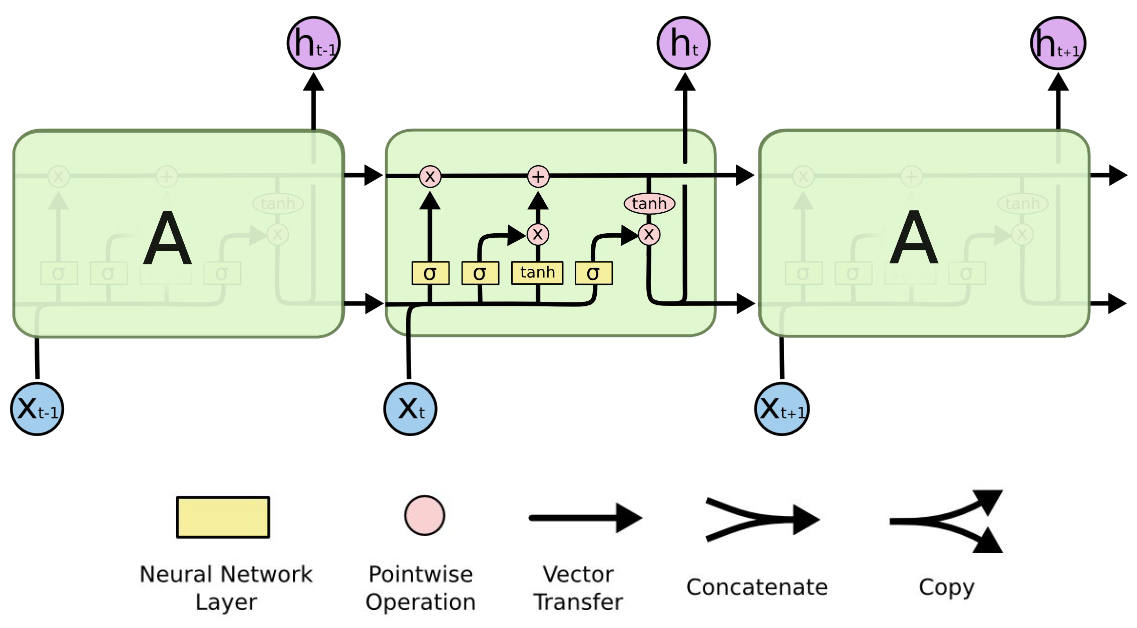
Komponenty:
- Dlouhodobá paměť: Udržuje informace pomocí paměťového článku (cell state), který prochází celou sítí.
- Brány: Řídí tok informací:
- Forget Gate: Rozhoduje, které informace z minulosti zapomenout.
- Input Gate: Vybírá nové informace k uložení.
- Output Gate: Určuje, které informace předat do výstupu.
Algoritmické kroky:
- Zapomínání nepotřebných informací (Forget Gate)
- Síť vyhodnotí, které informace z dlouhodobé paměti (cell state) jsou užitečné pro aktuální krok, a které je třeba zapomenout.
- Používá forget gate, jež generuje hodnoty mezi 0 (úplně zapomenout) a 1 (zachovat).
- Uložení nových informací (Input Gate)
- Input gate rozhoduje, jaké nové informace z aktuálního vstupu a skrytého stavu (hidden state) se přidají do dlouhodobé paměti.
- Vytvoří se kandidátské hodnoty (co by mohlo být uloženo) a input gate určí jejich důležitost.
- Aktualizace dlouhodobé paměti (Cell State Update)
- Dlouhodobá paměť (cell state) se aktualizuje:
- Staré nepotřebné informace se odstraní (násobení výstupem forget gate).
- Nové důležité informace se přidají (násobení výstupem input gate a kandidátskými hodnotami).
- Dlouhodobá paměť (cell state) se aktualizuje:
- Generování výstupu (Output Gate)
- Output gate určí, které části aktualizované dlouhodobé paměti se použijí pro výstup.
- Skrytý stav (hidden state) se aktualizuje na základě filtrované dlouhodobé paměti a předá se do dalšího kroku.
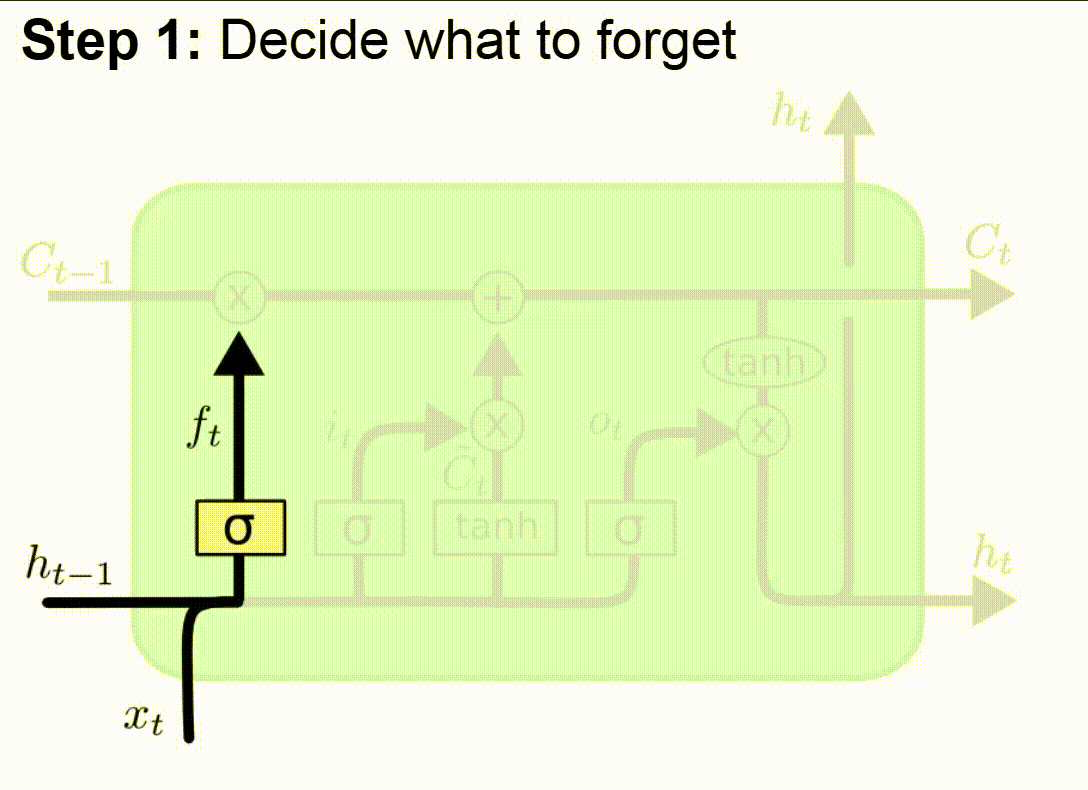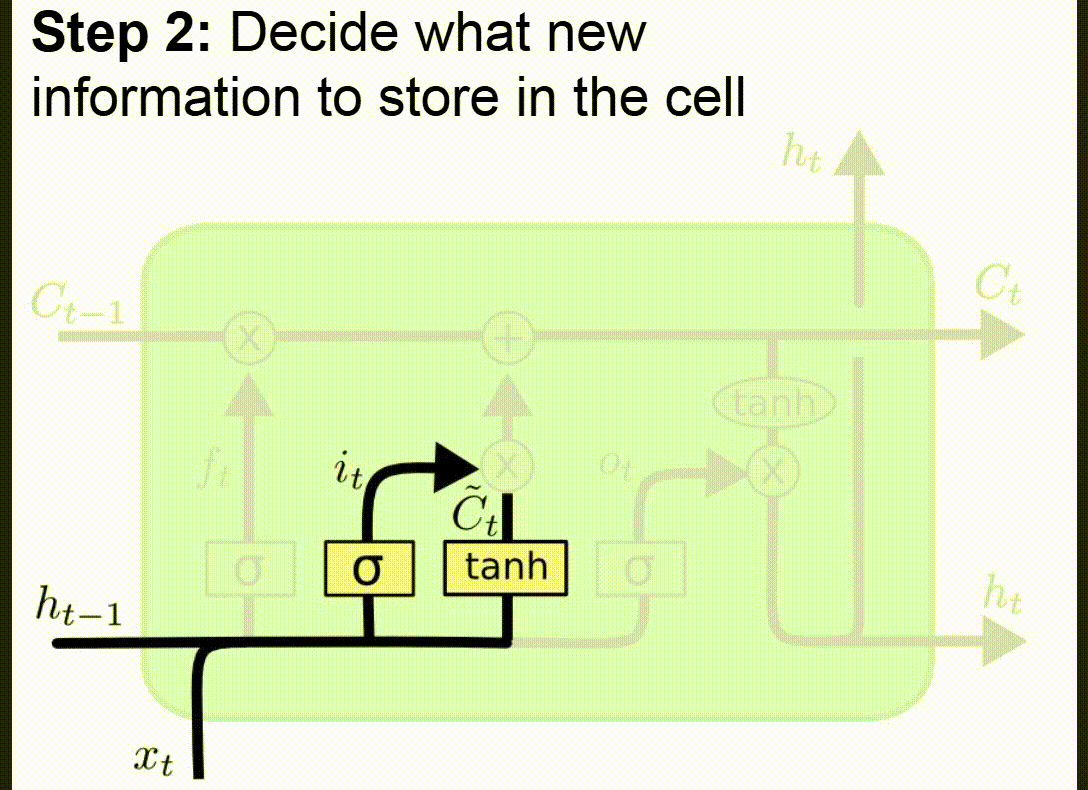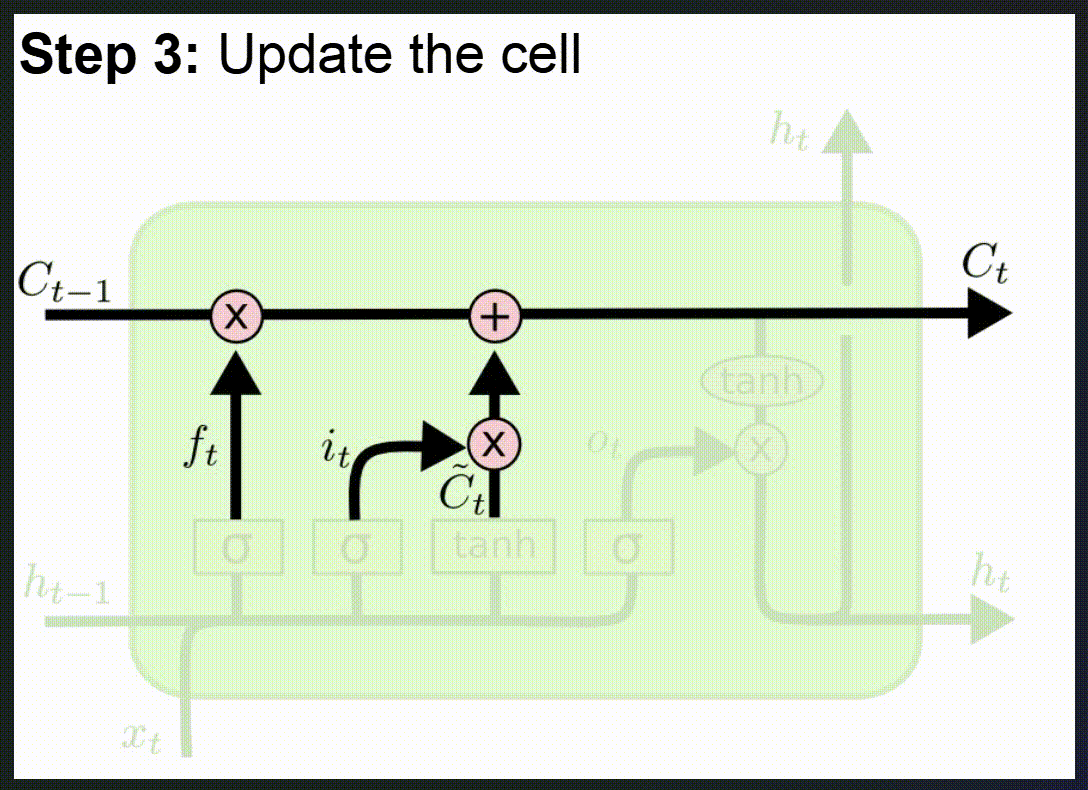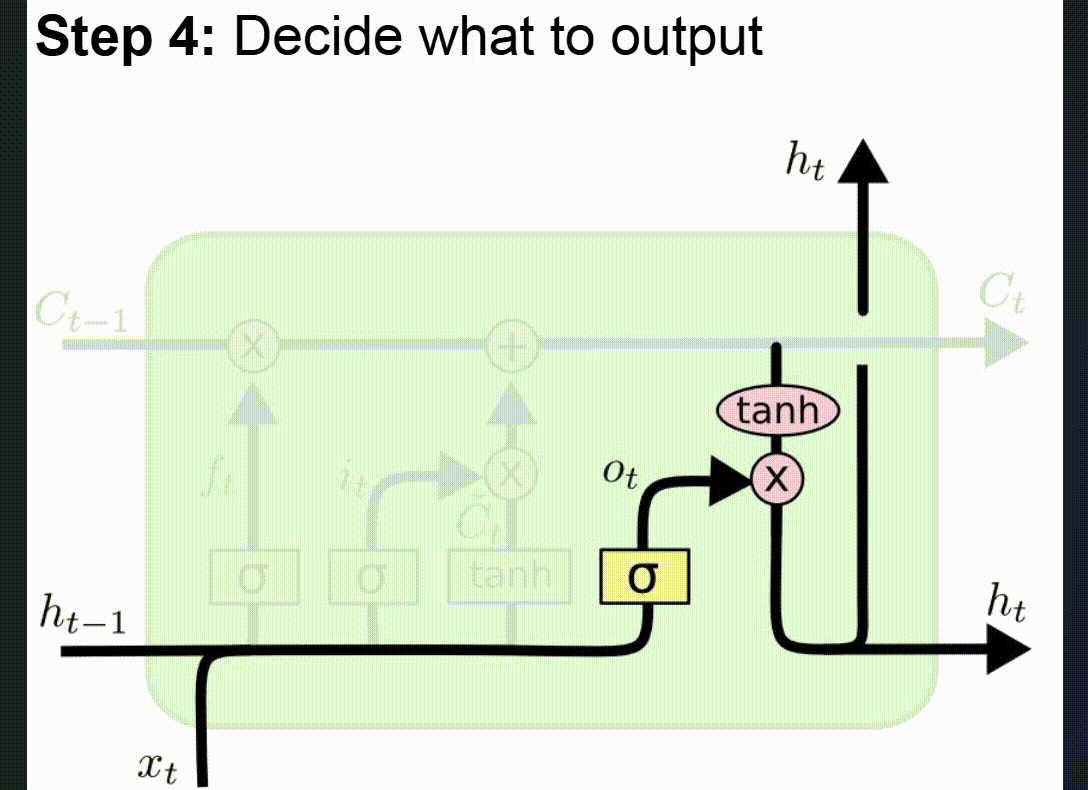
Proč funguje lépe než klasické RNN:
- Paměťový článek umožňuje přenášet informace přes mnoho kroků bez degradace.
- Brány dynamicky filtrují důležité/nedůležité informace.
Aplikace:
- Překlady mezi jazyky (např. Google Translate).
- Generování textu, rozpoznávání řeči.
GRU (Gated Recurrent Unit)¶
Architektura:
- Aktualizace stavu: Kombinuje předchozí stav a nový kandidátský stav v poměru daném update gate.
- Reset Gate: Omezuje vliv starých informací na výpočet nového stavu.
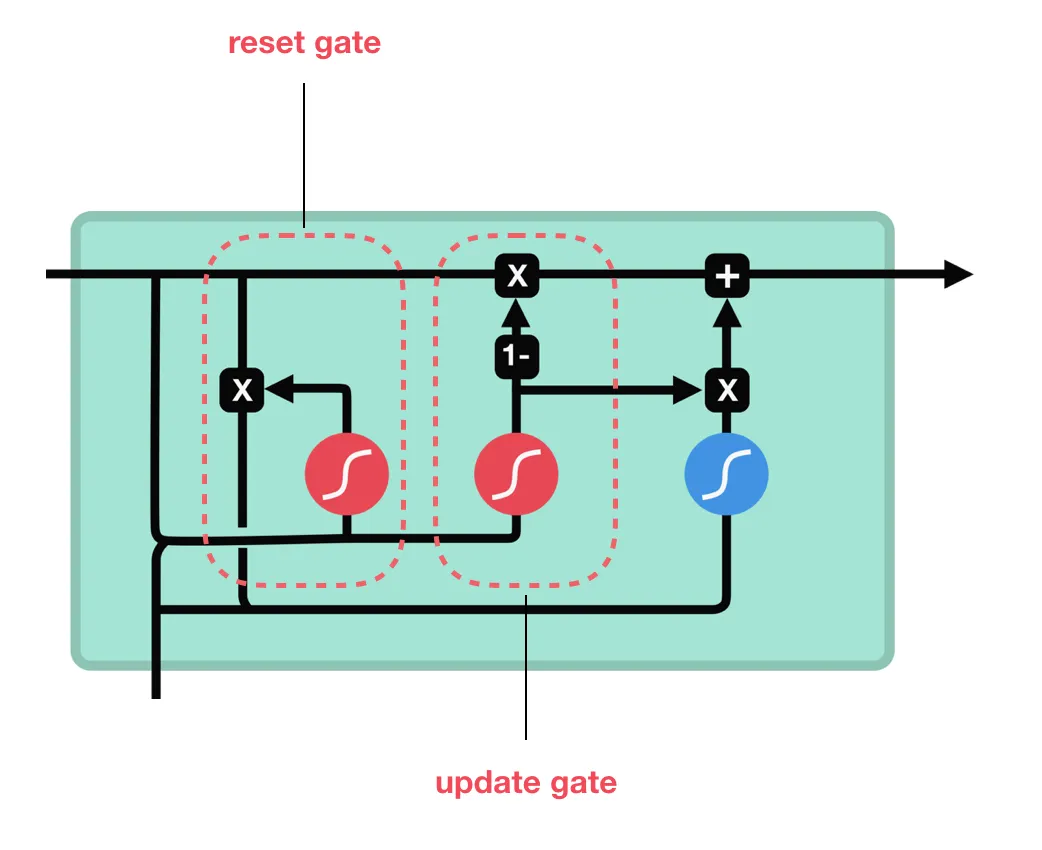
Komponenty:
- Zjednodušená verze LSTM: Slučuje paměťový článek a skrytý stav.
- 2 brány:
- Update Gate: Rozhoduje, kolik informací z minulosti zachovat.
- Reset Gate: Určuje, kolik minulosti ignorovat při výpočtu nového stavu.
Algoritmické kroky:
- Resetovací brána (Reset Gate)
- Určuje, které části předchozího skrytého stavu se ignorují při výpočtu nového kandidátského stavu.
- Umožňuje síti "zapomenout" irelevantní minulé informace pro aktuální krok.
- Aktualizační brána (Update Gate)
- Rozhoduje, kolik informací z předchozího skrytého stavu se zachová a kolik se přidá z nového vstupu.
- Generuje hodnoty mezi 0 (úplně ignorovat minulost) a 1 (zachovat vše).
- Aktualizace skrytého stavu
- Vytvoří se kandidátský stav kombinující nový vstup a filtrovaný předchozí stav (pomocí reset gate).
- Finální skrytý stav je směsí předchozího stavu a kandidátského stavu v poměru daném update gate.
Výhody oproti LSTM:
- Menší počet parametrů → rychlejší trénink.
- Efektivnější pro kratší sekvence.
Aplikace:
- Analýza sentimentu v textu.
- Predikce akciových trhů.
Srovnání architektur¶
| Typ sítě | Klíčový mechanismus | Paměť | Vhodné pro |
|---|---|---|---|
| Elman | Kontextová vrstva | Krátkodobá | Jednoduché sekvence (časové řady) |
| Hopfield | Asociativní energetické minimum | Stabilní stavy | Ukládání a rekonstrukce vzorů |
| LSTM | Brány + paměťový článek | Dlouhodobá | Složité sekvence (text, řeč) |
| GRU | 2 brány + sloučený stav | Efektivní krátkodobá | Rychlé úlohy s omezenými zdroji |
Neuroevoluce¶
Obecný princip neuroevoluce¶
- Metoda kombinující neuronové sítě a evoluční algoritmy k řešení optimalizačních úloh.
- Hlavní myšlenka: Simulace přirozeného výběru – lepší sítě (vyšší fitness) mají větší šanci předat své "geny" další generaci.
- Dva hlavní přístupy:
- Evoluce vah: Optimalizuje váhy v pevné architektuře sítě.
- Evoluce architektury: Mění strukturu sítě (počet vrstev, neuronů, spojení).
Algoritmy¶
GNARL (Genetic Algorithm for Neural Network Architecture and Rule Learning)¶
Základní princip:
- Evoluční algoritmus pro současnou optimalizaci architektury a vah sítě.
- Genom: Reprezentuje strukturu sítě (počet vrstev, spojení) a váhy.
Klíčové kroky:
- Inicializace: Náhodné populace různých architektur.
- Mutace: Přidávání/odebírání neuronů, změna spojení, perturbace vah.
- Křížení: Kombinace architektur rodičů (např. spojením vrstev).
- Selekce: Zachování sítí s nejlepší fitness (např. přesností na úloze).
Výhody:
- Flexibilní pro různé typy sítí.
- Nalezení kompaktních architektur.
Nevýhody:
- Pomalá konvergence kvůli velkému vyhledávacímu prostoru.
SANE (Symbiotic Adaptive Neuro-Evolution)¶
Základní princip:
- Symbióza dvou populací:
- Neurony: Jednotlivé neurony s vlastními geny (váhy, spojení).
- Modely (blueprinty): Kombinace neuronů do kompletních sítí.
Jak funguje:
- Každý model vybere neurony z populace a vytvoří síť.
- Fitness neuronu závisí na výkonu modelu v několika sítích (5 nejlepsi).
- Neurony z úspěšných modelů mají vyšší šanci na reprodukci.
Výhody:
- Modularita – neurony se specializují na konkrétní funkce.
- Efektivní pro paralelní evoluce.
Nevýhody:
- Omezená schopnost vytvářet hluboké architektury.
NEAT (NeuroEvolution of Augmenting Topologies)¶
Klíčové inovace:
- Historické značení (Historical Marking): Každé spojení má unikátní ID, což umožňuje bezpečné křížení různých architektur.
- Speciace: Rozdělení populace do druhů, které chrání inovace před vytlačením.
- Inkrementální růst: Začíná s minimální architekturou a postupně přidává neurony/spojení.
Fáze algoritmu:
- Mutace:
- Přidání spojení (s náhodnou váhou).
- Přidání neuronu (rozdělením existujícího spojení).
- Neodebírají se spojeni. Pouze se vypínají
- Křížení: Kombinuje geny rodičů na základě historických ID. (Například čas vytvořeni)
- Speciace: Sítě se stejnou strukturou jsou ve stejném druhu.
- A fitness se rozděluje mezi site ve stejném druhu.
- Fitnes / velikost populace daneho druhu
- Aby se ochránily nove méně efektivní site
- A fitness se rozděluje mezi site ve stejném druhu.
Výhody:
- Efektivní hledání optimálních architektur.
- Minimalizuje redundanci (konkurenci mezi zcela odlišnými strukturami).
Aplikace: Řízení robotů, hry (např. AI pro Mario).
HyperNEAT (Hypercube-based NEAT)¶
Základní myšlenka:
- Síť je generována nepřímo pomocí Compositional Pattern-Producing Network (CPPN).
- CPPN kóduje pravidla pro vytváření vah na základě geometrie problému (např. symetrie, opakující se vzory).
Klíčové komponenty:
- Substrát: Definuje pozice neuronů ve vstupní/výstupní vrstvě (např. 2D mřížka pro obraz).
- CPPN: Bere souřadnice dvou neuronů a vrací váhu jejich spojení.
Výhody:
- Škálovatelnost: Generuje obří sítě s pravidelnou strukturou.
- Využívá geometrii problému (např. symetrie v obraze).
Aplikace: Generování pohybových vzorců pro roboty, umělé umění.
Srovnání algoritmu¶
| Algoritmus | Silné stránky | Omezení | Vhodné pro |
|---|---|---|---|
| GNARL | Flexibilita architektury | Pomalá konvergence | Malé až střední sítě |
| SANE | Modularita, paralelizace | Mělké architektury | Úlohy s jasnou modularitou |
| NEAT | Rychlý růst komplexních struktur | Náročné na výpočty | Řízení, hry |
| HyperNEAT | Škálovatelnost, geometrické vzory | Omezené na geometrické úlohy | Robotika, generativní modely |